Part 4 in the “Building Event-Driven Microservices with Hazelcast” series
Introduction
In the first three articles, we built an event sourcing framework with a Jet pipeline and materialized views. Each service is self-contained — it owns its events, its views, and its data. And one of the things that makes event-driven architecture powerful is that event publishing is fire-and-forget. The publisher doesn’t know or care who’s receiving the messages, or whether anyone acted on them properly.
But someone cares. Probably your boss.
That decoupling is a feature, not a bug — it’s exactly what gives you the independence to evolve services separately. If you wanted to add a loyalty program based on orders placed, you wouldn’t touch a single line of existing code. You’d build the new functionality and subscribe it to OrderCreated events. Done. No coordination, no release trains, no “can you add a field to your response for us.”
But that same independence becomes a problem when a business operation requires coordination. Placing an order in our eCommerce system spans four services:
- Order Service creates the order
- Inventory Service reserves stock
- Payment Service charges the customer
- Order Service confirms the order
If payment fails after stock is reserved, we need to release the stock. If the inventory service is down, we need to cancel the order. The fire-and-forget publisher doesn’t know any of this happened — and nobody else is keeping track unless we build something that does.
Now — a real eCommerce system wouldn’t cancel an order just because the inventory service hiccupped. You’d create a backorder, or queue the reservation for retry, or do whatever it takes to keep the customer’s money. Nobody in the business is going to say “yeah, let’s give up on that sale because a container restarted.” But we’re building a framework to demonstrate microservice patterns, not to compete with Shopify. The cancel-and-compensate flow shows sagas at their most illustrative: forward steps, failure detection, compensation, and state tracking across services. That’s the machinery we want to examine. So we went with the version that best shows how the pattern works, not the version that best sells laptops.
This is the distributed transaction problem, and sagas are the solution.
Why Sagas? Because the Alternative Is Worse.
We didn’t adopt event sourcing because it was fashionable. We adopted it because the alternative — mutable state scattered across services with no audit trail — was worse. Sagas are the same kind of choice.
When a business operation touches one database, you wrap it in a transaction. ACID gives you atomicity: either all the changes commit or none of them do. Every developer learns this in their first database course, and it works.
But our order fulfillment touches four services, each with its own data. A single database transaction can’t span them. So you reach for two-phase commit — 2PC — the textbook answer for distributed transactions. And that’s where the trouble starts.
2PC works by appointing a coordinator that asks each participant “can you commit?” and then, once everyone says yes, tells them all to go ahead. The problem is what happens between those two phases. Every participant is holding locks — on inventory rows, on payment records, on order state — while waiting for the coordinator’s decision. In a monolith, that wait is microseconds. Across a network, it’s milliseconds at best, and if the coordinator is slow or the network partitions, those locks can be held for seconds. Or longer.
Think about what that means for throughput. While one order is sitting in that limbo state between “prepare” and “commit,” no other transaction can touch those same inventory rows. At 50 orders per second, you’ve got 50 sets of distributed locks competing for the same resources, each one waiting on network round-trips to a coordinator that is itself a single point of failure. If the coordinator crashes mid-protocol, those locks stay held until someone intervenes manually. The participants are stuck — they’ve promised to commit but haven’t been told to, and they can’t unilaterally release the locks without risking inconsistency.
It’s not that 2PC is theoretically wrong. It works fine in environments where all participants are on the same local network, latency is sub-millisecond, and the coordinator never fails. That environment is called “a single database server.” Once you’ve distributed beyond that, you’re fighting physics.
Sagas take a fundamentally different approach. Instead of one big atomic transaction with distributed locks, you execute a sequence of local transactions — each one fast, each one touching only one service’s data, each one committing immediately. If step 3 fails, you don’t roll back steps 1 and 2 by releasing locks. You compensate — you issue new transactions that undo the business effect of the earlier steps. Reserve stock, then charge payment, then… payment fails? Issue a stock release. The saga doesn’t pretend the work never happened. It acknowledges what happened and fixes it forward.
The trade-off is that you give up the clean atomicity of “all or nothing” and accept eventual consistency — a window of time where stock is reserved but payment hasn’t been attempted yet, or payment has been charged but the order isn’t confirmed. In our system, that window is typically under a second. For the user, the order is “processing.” For the system, the saga is in flight. And if something fails, compensation events fire and the system converges to a consistent state — just not instantaneously.
Choreography and Orchestration
There are two ways to coordinate a saga. They represent genuinely different architectural philosophies, and neither is universally right.
Choreography: Services React to Events
In a choreographed saga, there’s no coordinator. Each service listens for events that concern it and reacts:
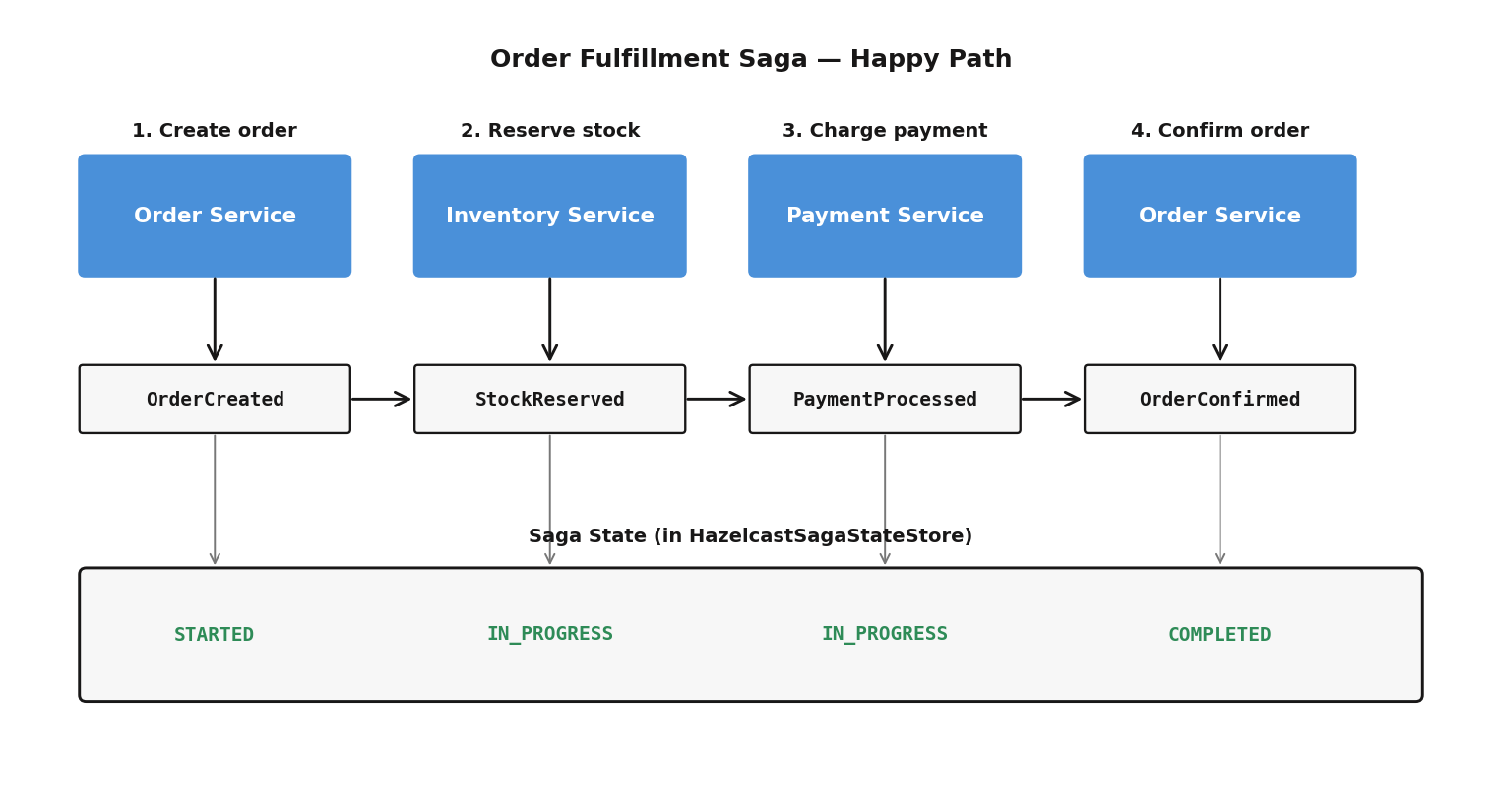
Order Service publishes OrderCreated -->
Inventory Service hears it, reserves stock, publishes StockReserved -->
Payment Service hears it, charges customer, publishes PaymentProcessed -->
Order Service hears it, confirms order
The flow emerges from the interactions between services. No single component knows the full sequence. Each service knows only “when I see event X, I do Y and publish Z.”
Orchestration: A Central Controller Directs the Flow
In an orchestrated saga, one component — the orchestrator — knows the whole sequence and directs each step:
Orchestrator --> "Order Service, create order" Orchestrator --> "Inventory Service, reserve stock" Orchestrator --> "Payment Service, charge customer" Orchestrator --> "Order Service, confirm order"
The orchestrator is a state machine. It tracks where the saga is, what comes next, and what to undo if something fails.
Choosing Between Them
Choreography is the simpler choice when your saga is a linear chain — A triggers B triggers C triggers D — and the services are already publishing events for other reasons. If your system is event-driven (ours is), choreographed sagas are almost free. The services are already emitting events. The saga is just another consumer. No new infrastructure, no single point of failure, and each service stays fully independent.
But choreography gets painful as the flow gets complex. Say step 2 needs to branch — charge a credit card or apply store credit, depending on the payment method. Now you’re encoding conditional logic across multiple listeners that can’t see each other. If someone asks “what does this saga actually do, end to end?” the answer is “go read three listener classes in three different services and piece it together.” For a four-step linear chain, fine. For a ten-step flow with branches and conditional skips, that’s a mess.
That’s where orchestration earns its keep. The entire saga — forward steps, compensation steps, timeouts, retry logic — lives in a single definition file. You read it top to bottom. You can add per-step timeouts, per-step retries. The caller can wait for the result synchronously. The cost is coupling: the orchestrator needs to know about every service’s endpoint, and it becomes a component you have to keep running.
A rough rule of thumb:
Start with choreography when the saga is a linear chain with fewer than about five steps, the services already publish events, and you don’t need a synchronous response. Move to orchestration when you need branching or conditional logic, per-step timeout and retry control, a synchronous success/failure response for the caller, or when the saga has gotten complex enough that nobody can trace it across listeners without a whiteboard.
We started with choreography for order fulfillment because it’s a clean four-step chain and our entire architecture is already built around events. Later, when we needed synchronous responses for certain API paths and wanted per-step timeout control, we added orchestration as a second option. Both patterns coexist in the framework, running against the same saga state store. We’ll cover the orchestration implementation and how we run both side by side in a later article.
The Order Fulfillment Saga
Here’s the full flow for the choreographed version:
Event Context Propagation
Every saga event carries metadata that links the chain together:
// These fields are present on every saga event String sagaId; // Links all events in one saga instance String correlationId; // Links to the original API request String sagaType; // "OrderFulfillment" int stepNumber; // Which step (0, 1, 2, 3) boolean isCompensating; // True for compensation events
The sagaId is generated when the order is created and propagated through every subsequent event. That’s how the Inventory Service knows which saga a StockReserved event belongs to, and how the Payment Service gets the payment details — amount, currency, method — from the StockReserved event’s context fields.
Implementing Saga Listeners
Each service has a saga listener that subscribes to relevant events via Hazelcast ITopic. Here’s the Payment Service’s:
@Component
public class PaymentSagaListener {
public PaymentSagaListener(
@Qualifier("hazelcastClient") HazelcastInstance hazelcast,
PaymentService paymentService,
SagaStateStore sagaStateStore) {
// Listen for StockReserved --> process payment
ITopic<GenericRecord> stockReservedTopic = hazelcast.getTopic("StockReserved");
stockReservedTopic.addMessageListener(message -> {
GenericRecord event = message.getMessageObject();
String sagaId = event.getString("sagaId");
String orderId = event.getString("orderId");
String amount = event.getString("paymentAmount");
String currency = event.getString("paymentCurrency");
String method = event.getString("paymentMethod");
paymentService.processPaymentForOrder(
orderId, customerId, amount, currency, method,
sagaId, event.getString("correlationId")
);
});
// Listen for PaymentRefundRequested --> process refund
ITopic<GenericRecord> refundTopic = hazelcast.getTopic("PaymentRefundRequested");
refundTopic.addMessageListener(message -> {
GenericRecord event = message.getMessageObject();
String paymentId = event.getString("paymentId");
String sagaId = event.getString("sagaId");
paymentService.refundPaymentForSaga(
paymentId, "Saga compensation", sagaId,
event.getString("correlationId")
);
});
}
}
The listener uses @Qualifier(“hazelcastClient”) — it connects to the shared cluster, not the embedded instance. That’s the dual-instance architecture from Part 2. Each listener is a plain @Component that Spring creates on startup; the ITopic subscription stays active for the life of the service. And the listener itself doesn’t contain business logic — it unpacks the event, delegates to the service layer, and gets out of the way.
Compensation: Undoing Work
When a step fails, we need to undo the work completed by previous steps. This is compensation — often described as the saga equivalent of a rollback, though it isn’t really a rollback at all. More on that in a minute.
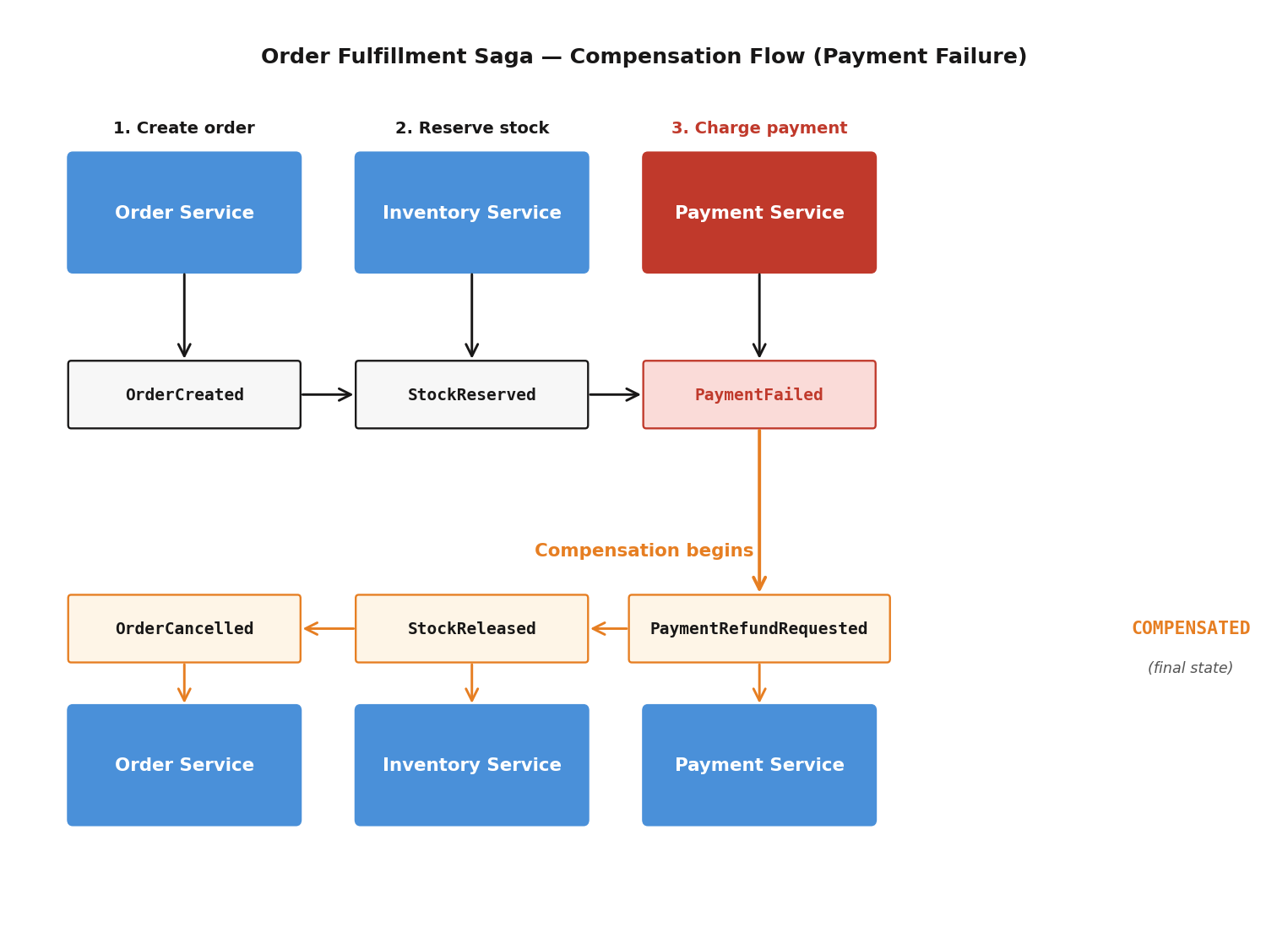
Compensation Flow: Payment Fails
Compensation Flow: Stock Unavailable
StockReservationFailed event
|
'---> Order Service
'-- Cancels order (status: CANCELLED)
'-- No stock release needed (nothing was reserved)
Saga finalized as COMPENSATED
The Compensation Registry
A CompensationRegistry maps each forward event to its compensating event and responsible service:
@Configuration
public class ECommerceCompensationConfig {
@Bean
public CompensationRegistrar ecommerceCompensations(CompensationRegistry registry) {
// Step 0: OrderCreated --> compensate with OrderCancelled
registry.register("OrderCreated", "OrderCancelled", "order-service");
// Step 1: StockReserved --> compensate with StockReleased
registry.register("StockReserved", "StockReleased", "inventory-service");
// Step 2: PaymentProcessed --> compensate with PaymentRefunded
registry.register("PaymentProcessed", "PaymentRefunded", "payment-service");
// Step 3: OrderConfirmed --> no compensation (terminal success)
return () -> {};
}
}
This is the one place that documents the entire saga structure. Even though the execution is distributed across listeners, the registry makes the step-to-compensation mapping readable in a single file. That’s something people miss about choreography — it doesn’t mean the structure is undocumented, it means the structure is declared separately from the execution.
Saga State Tracking
The SagaState class is an immutable state machine that tracks each saga instance:
public class SagaState implements Serializable {
private final String sagaId;
private final String sagaType; // "OrderFulfillment"
private final String correlationId;
private final SagaStatus status; // STARTED --> IN_PROGRESS --> COMPLETED
private final List<SagaStepRecord> steps;
private final Instant startedAt;
private final Instant deadline; // Absolute timeout
}
Status transitions:
STARTED --> IN_PROGRESS --> COMPLETED (happy path) STARTED --> IN_PROGRESS --> COMPENSATING --> COMPENSATED (failure + recovery) STARTED --> IN_PROGRESS --> TIMED_OUT --> COMPENSATING --> COMPENSATED (timeout) STARTED --> IN_PROGRESS --> FAILED (unrecoverable)
The state lives in a HazelcastSagaStateStore backed by an IMap on the shared cluster. Every service can read and update saga state because they all connect to the same shared cluster via the client instance.
Each step gets recorded:
public class SagaStepRecord implements Serializable {
private final int stepNumber;
private final String eventType;
private final StepStatus status; // PENDING, COMPLETED, FAILED, COMPENSATED
private final Instant completedAt;
private final String failureReason;
}
Timeout Handling
Sagas can get stuck. A service might be down, a message might be lost, or a listener might throw an unhandled exception. Without timeout detection, a stuck saga hangs forever — stock reserved but never charged, or charged but never confirmed.
The SagaTimeoutDetector is a scheduled service that runs in each service instance:
@Component
public class SagaTimeoutDetector {
@Scheduled(fixedDelayString = "${saga.timeout.check-interval:5000}")
public void detectTimeouts() {
List<SagaState> timedOut = sagaStateStore.findTimedOutSagas(
maxBatchSize
);
for (SagaState saga : timedOut) {
sagaStateStore.markTimedOut(saga.getSagaId());
if (autoCompensate) {
compensator.compensate(saga);
}
applicationEventPublisher.publishEvent(
new SagaTimedOutEvent(saga)
);
sagaMetrics.recordSagaTimedOut(saga.getSagaType());
}
}
}
Every five seconds, it looks for sagas that have blown past their deadline. When it finds one, it marks it timed out, triggers compensation for whatever steps already completed, publishes a Spring event for logging and alerting, and records the metric.
Timeout behavior is configurable per service:
saga:
timeout:
enabled: true
check-interval: 5000 # Check every 5 seconds
default-deadline: 30000 # 30-second default timeout
auto-compensate: true # Auto-trigger compensation
max-batch-size: 100 # Process up to 100 timeouts per check
saga-types:
OrderFulfillment: 60000 # 60 seconds for order fulfillment
The Order Fulfillment saga gets 60 seconds — longer than the 30-second default — because it spans four services and includes payment processing, which can be slow. Choosing the right timeout value is harder than it sounds, and we have quite a bit more to say about that in the next article.
Monitoring Sagas
The SagaMetrics class exposes counters and timers to Prometheus:
| Metric | What It Tells You |
|---|---|
| saga.started | How many sagas are being created |
| saga.completed | How many succeed end-to-end |
| saga.compensated | How many required rollback |
| saga.timedout | How many exceeded their deadline |
| saga.duration (p95) | How long sagas are taking |
| saga.compensation.duration (p95) | How long compensation takes |
The pre-provisioned Saga Dashboard in Grafana visualizes active saga counts, throughput rates by saga type, duration percentiles, success rates, timeout detection rates, and compensation breakdowns. Pre-configured alerts fire on high failure rates, timeouts, compensation failures, and success rate drops below 90%.
The dashboard is useful. But the metric that actually saved us during a sustained load incident was dead simple: saga.timedout plotted alongside saga.completed. When timeouts exceeded completions, we knew we had a systemic problem, not just a few slow sagas. More on that story next time.
Design Decisions and Trade-offs
Eventual Consistency
Sagas provide eventual consistency, not immediate consistency. Between the time stock is reserved and payment is processed, the system is in a “pending” state. That’s intentional — the trade-off buys us service independence and availability. For our use case, the consistency window is sub-second. For domains where that’s not acceptable (financial settlement, medical records), you’d need stronger guarantees.
Idempotency
Saga listeners must be idempotent. ITopic delivery is at-most-once in Hazelcast, but the timeout detector might trigger compensation for a saga that was actually processing — just slowly. If the original flow completes after compensation starts, the system has to handle the overlap gracefully.
SagaState handles this with updateOrAddStep, which replaces by step number. A step can’t be recorded twice.
Compensation Is Not Rollback
This is worth being explicit about, because the terminology invites confusion.
Compensation undoes the business effect, not the technical state. When we “refund a payment,” we don’t delete the payment record. We create a new PaymentRefundedEvent that changes the payment status to REFUNDED. The event history preserves the full story: payment was processed, then refunded. If an auditor comes asking, the trail is complete.
This fits naturally with event sourcing. The compensation is just another event. Nothing is erased, nothing is pretended away. The system records what actually happened, including the part where something went wrong and was corrected.
Summary
The saga pattern solves distributed transaction coordination without distributed locks:
Choreographed sagas fit naturally with event sourcing — each service reacts to events independently, no coordinator required. Orchestrated sagas earn their place when flows grow complex, need synchronous responses, or require per-step control. Compensation provides rollback-like semantics through new events, preserving the full history. Timeout detection catches stuck sagas. Saga state tracking gives you a complete audit trail.
The result is a system where four independent services coordinate a complex business transaction without any service knowing about the others — they only know about events. The cost is that you’re managing a distributed state machine instead of a database transaction. But the alternative — distributed locks held across network calls while a coordinator decides everyone’s fate — is worse.
Next up: Saga Timeouts — When Distributed Things Go Wrong
Previous: Materialized Views for Fast Queries
