Part 7 in the “Building Event-Driven Microservices with Hazelcast” series
Introduction
A commercial airliner doesn’t fall out of the sky when an engine fails. It keeps flying. The remaining engine provides enough thrust to reach the nearest airport, the crew follows a well-rehearsed procedure, and the passengers — ideally — never know how close things got. Aviation engineers figured this out decades ago: you can’t prevent every failure, so you build the system to keep working when parts of it stop. (There’s even a great acronym for it — ETOPS, which officially stands for Extended Twin-engine Operations Performance Standards, but which pilots will tell you really means “Engines Turn Or Passengers Swim.”)
Microservices need the same philosophy. Not because individual services fail as dramatically as a jet engine, but because they fail far more often. A garbage collection pause. A network blip. A downstream provider having a bad day. A deployment rolling through the cluster at 2 AM. In a monolith, these are minor hiccups — the kind of thing you might not even notice in the logs. In a distributed system where five services coordinate through asynchronous events, a hiccup in one service can propagate to all five in the time it takes to brew a cup of coffee.
And the ways things go wrong are… creative. The catalog of distributed system failure modes is large enough to fill a textbook. Several textbooks, actually — and people have. Too many for a single pattern or a single blog post.
So we’re spending the next three posts on resilience. This one covers circuit breakers and retry — protecting saga listeners when downstream services misbehave. Part 8 tackles the transactional outbox pattern, which guarantees events aren’t lost between producer and consumer. And Part 9 adds dead letter queues and idempotency guards — the safety nets for events that fail permanently or arrive more than once. Three different failure modes, three different mechanisms.
Back in Part 4, we built a choreographed saga for order fulfillment. Three services — Inventory, Payment, and Order — coordinate through Hazelcast ITopic events published on a shared cluster. The happy path works beautifully. Without resilience patterns, though, a single struggling service can drag the whole saga down with it. A slow Payment Service fills up the Inventory Service’s thread pool with blocked calls. A transient network error permanently loses an event. A burst of failures overwhelms everything simultaneously.
That’s what we’re fixing.
The Problem: Cascading Failures
Here’s the order fulfillment saga on a good day:
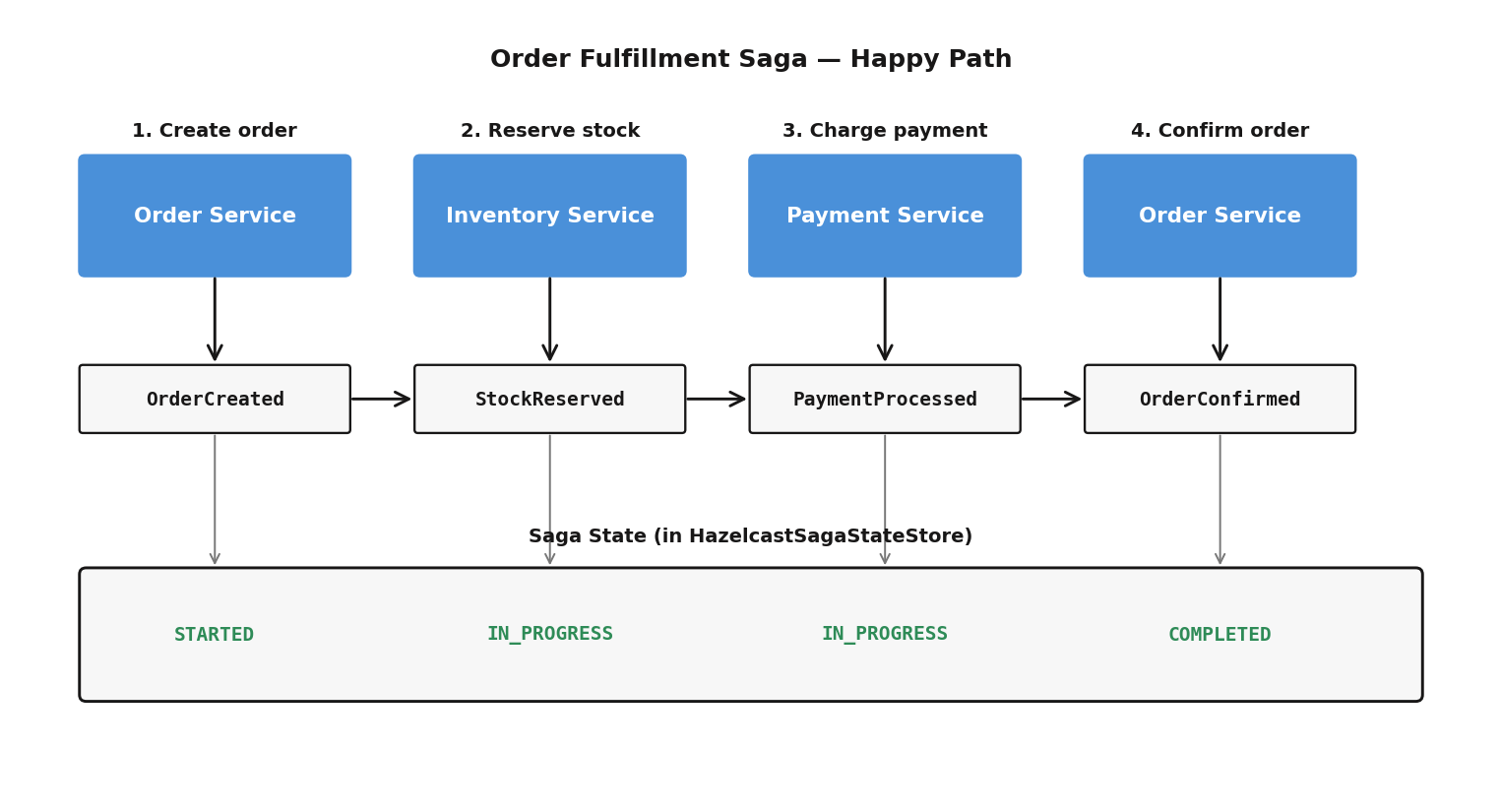
Each step is an ITopic message on the shared Hazelcast cluster. Each listener calls a local service method — IMap operations, Jet pipeline processing, further ITopic publishing. Events flow, state updates, everyone’s happy.
Now imagine the Payment Service is having a rough morning. Some downstream payment provider is dragging, and every StockReserved event that arrives takes 30 seconds to process instead of the normal 50 milliseconds. Without any resilience mechanism, here’s what unfolds:
- Inventory keeps publishing StockReserved events at the normal rate
- Payment’s listener thread pool fills up with slow calls
- New events queue behind the blocked threads
- ITopic backpressure eventually slows the shared cluster itself
- Other listeners on the same cluster — including Inventory and Order — start seeing delays
- The entire saga grinds to a halt
One service had a problem. Now every service has a problem. This is a cascade failure, and it’s the defining hazard of distributed architectures. The shared communication fabric that makes coordination possible is the same fabric that propagates failure.
Enter Resilience4j
The patterns we need — circuit breakers, retry with backoff, bulkheads, rate limiters — have been well understood for years. Netflix popularized them in the Java world with Hystrix, which became the standard library for microservice resilience through most of the 2010s. But Netflix put Hystrix into maintenance mode in 2018 and eventually stopped development entirely.
The successor that emerged is Resilience4j. It’s a lightweight fault tolerance library for Java 8+ built around functional composition — you wrap a Supplier or Runnable with decorators, and the decorators handle the resilience logic. It’s not just a circuit breaker library, though that’s what most people know it for. It actually provides six core modules: circuit breaker, retry, bulkhead (resource isolation), rate limiter, time limiter, and cache. Each is standalone. You pick what you need and leave the rest on the shelf.
There are other options — Failsafe is a solid zero-dependency alternative, and Alibaba’s Sentinel targets high-traffic rate limiting scenarios. But Resilience4j has become the de facto choice for Spring Boot microservices. The Spring integration is mature, Micrometer metrics work out of the box, and @ConfigurationProperties binding means your resilience settings live in the same YAML as everything else. For our framework, we’re using two of the six modules: CircuitBreaker and Retry.
Circuit Breakers: Automatic Service Isolation
A circuit breaker does what it sounds like. It monitors the failure rate of an operation and automatically stops calling it when failures exceed a threshold — the same idea as the breaker panel in your house. Too much current flows through the circuit, the breaker trips, the wiring doesn’t catch fire. In our case, “too much current” means too many failed calls, and “the wiring” is every other service sharing that communication path.
Three States
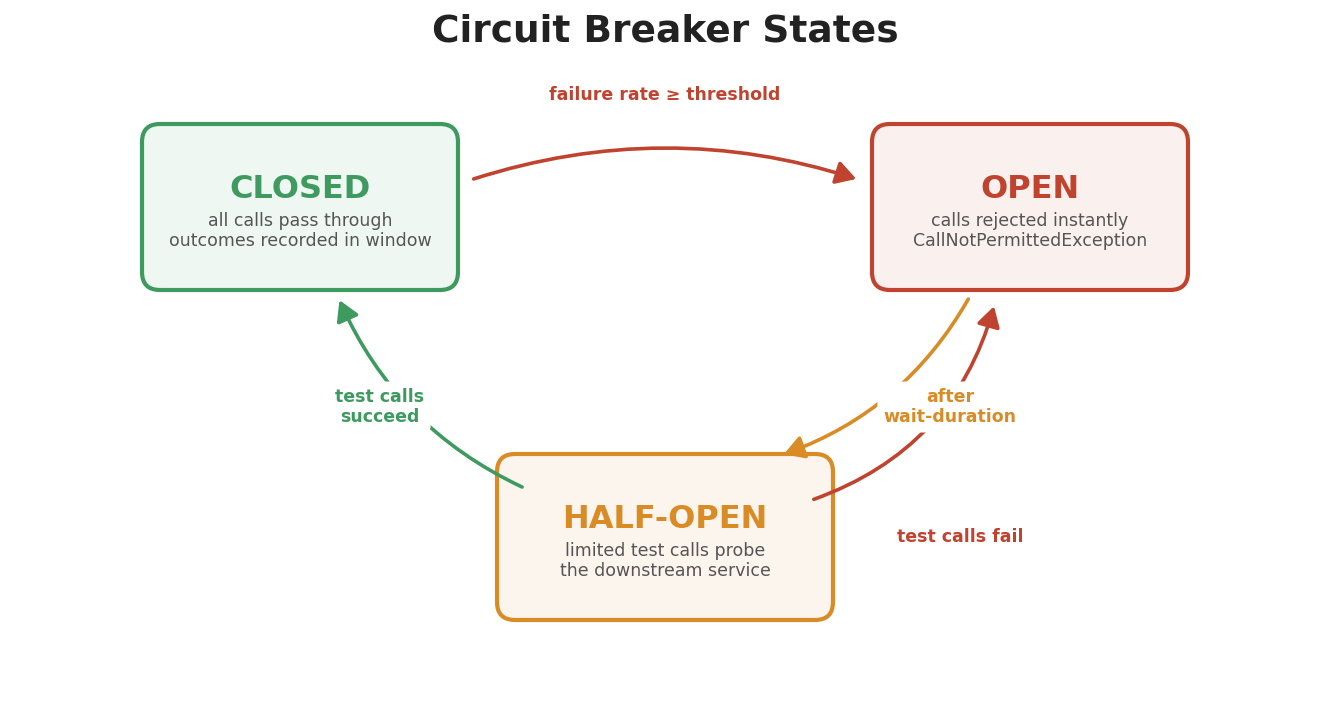
CLOSED is normal operation. All calls pass through, and the circuit breaker quietly records outcomes in a sliding window. OPEN means the breaker has tripped — all calls are immediately rejected with a CallNotPermittedException, and no load reaches the downstream service at all. HALF-OPEN is the recovery probe: a limited number of test calls pass through. If they succeed, the breaker returns to CLOSED. If they fail, back to OPEN. Rinse and repeat until the downstream service gets its act together.
The Framework’s ResilientServiceInvoker
Rather than sprinkling Resilience4j decorators at every call site, we centralized everything into ResilientServiceInvoker:
public class ResilientServiceInvoker implements ResilientOperations {
private final CircuitBreakerRegistry circuitBreakerRegistry;
private final RetryRegistry retryRegistry;
private final ResilienceProperties properties;
public <T> T execute(final String name, final Supplier<T> operation) {
if (!properties.isEnabled()) {
return operation.get();
}
final CircuitBreaker circuitBreaker = circuitBreakerRegistry.circuitBreaker(name);
final Retry retry = retryRegistry.retry(name);
final Supplier<T> decoratedSupplier = CircuitBreaker.decorateSupplier(circuitBreaker,
Retry.decorateSupplier(retry, operation));
try {
return decoratedSupplier.get();
} catch (CallNotPermittedException e) {
logger.warn("Circuit breaker '{}' is OPEN — rejecting call", name);
throw new ResilienceException(
"Circuit breaker '" + name + "' is open, call rejected", name, e);
} catch (Exception e) {
logger.error("Operation '{}' failed after retries: {}", name, e.getMessage());
throw new ResilienceException(
"Operation '" + name + "' failed after retries", name, e);
}
}
}
A few things to notice here. Each call to execute(“inventory-stock-reservation”, …) creates or retrieves a circuit breaker and retry instance with that name. This means each saga step gets its own independent circuit breaker — a payment failure won’t trip the inventory breaker.
The decoration order matters: retry wraps the operation first, then the circuit breaker wraps the retry. So the circuit breaker sees the final outcome after all retries are exhausted. A transient failure that succeeds on the second attempt counts as a success for the circuit breaker. If you stacked them the other way around, every individual failed attempt would register as a circuit breaker failure, and you’d trip the breaker much faster than you intended.
And there’s a kill switch. When framework.resilience.enabled=false, the execute method just calls the operation directly. Zero overhead. This matters for testing and for environments where resilience is handled at a different layer — a service mesh, maybe, or a cloud provider’s load balancer.
The ResilientOperations Interface
We extract an interface from the concrete class:
public interface ResilientOperations {
<T> T execute(String name, Supplier<T> operation);
void executeRunnable(String name, Runnable operation);
<T> CompletableFuture<T> executeAsync(String name, Supplier<CompletableFuture<T>> operation);
}
This is the same workaround we used for ServiceClientOperations in Part 6. Java 25’s Mockito inline mock maker can’t mock concrete classes in certain JVM configurations, so you extract an interface and mock that instead. Not the most glamorous reason to create an abstraction, but it works.
Three Flavors
The invoker supports three calling patterns:
// Synchronous — returns a value
String result = invoker.execute("orderSaga", () -> processEvent(event));
// Fire-and-forget — void operation
invoker.executeRunnable("paymentListener", () -> publishToTopic(event));
// Async — returns CompletableFuture
CompletableFuture<Product> future = invoker.executeAsync("inventory-stock-reservation",
() -> inventoryService.reserveStockForSaga(productId, quantity, ...));
The async variant is the one our saga listeners actually use — inventory, payment, and order service calls all return CompletableFuture.
Wiring into the Saga Listeners
The saga listeners from Part 4 now inject ResilientOperations as an optional dependency:
@Component
public class InventorySagaListener {
private final ProductService inventoryService;
private final HazelcastInstance hazelcast;
private ResilientOperations resilientServiceInvoker;
@Autowired(required = false)
public void setResilientOperations(ResilientOperations resilientServiceInvoker) {
this.resilientServiceInvoker = resilientServiceInvoker;
}
That @Autowired(required = false) is doing important work. If resilience is disabled — or if the Resilience4j dependency isn’t even on the classpath — the listener still functions. It just calls the service directly, no wrapping. The saga worked before we added resilience; it should keep working without it.
Each listener has a helper that handles the null check:
private <T> CompletableFuture<T> executeWithResilience(
final String name, final Supplier<CompletableFuture<T>> operation) {
if (resilientServiceInvoker != null) {
return resilientServiceInvoker.executeAsync(name, operation);
}
return operation.get();
}
And the actual saga step looks like this:
executeWithResilience("inventory-stock-reservation",
() -> inventoryService.reserveStockForSaga(
productId, quantity, orderId, sagaId, correlationId,
customerId, total, currency, "CREDIT_CARD"
)
).whenComplete((product, error) -> {
if (error != null) {
sendToDeadLetterQueue(record, "OrderCreated", error);
} else {
logger.info("Stock reserved for saga: productId={}, quantity={}, orderId={}, sagaId={}",
productId, quantity, orderId, sagaId);
}
});
The circuit breaker name inventory-stock-reservation is specific to this saga step. Each step across the three services gets its own name and its own circuit breaker:
| Circuit Breaker Name | Saga Step | Service |
|---|---|---|
| inventory-stock-reservation | Reserve stock on OrderCreated | Inventory |
| inventory-stock-release | Release stock on compensation | Inventory |
| payment-processing | Process payment on StockReserved | Payment |
| payment-refund | Refund payment on compensation | Payment |
| order-confirmation | Confirm order on PaymentProcessed | Order |
| order-cancellation | Cancel order on compensation | Order |
Six independent circuit breakers. If payment processing is struggling, the inventory breakers stay closed and keep doing their job.
Retry with Exponential Backoff
Transient failures — network blips, temporary overload, brief GC pauses — are the most common failure mode in distributed systems. Most of them resolve on their own within seconds. Retry is the first line of defense.
The Thundering Herd
But naive retry — retry immediately, same interval, keep hammering — can make things actively worse. Picture this: a service buckles under load, and 100 clients all get errors simultaneously. They all retry at 500ms. The service sees a spike of 100 simultaneous requests. It fails again. They all retry at 1000ms. Another spike. Same result.
This is the thundering herd problem. Everyone backs off at the same fixed interval, and everyone comes stampeding back at the same moment. The retry mechanism that was supposed to help is the thing keeping the service down.
Exponential backoff breaks the herd apart:
Attempt 1: immediate Attempt 2: wait 500ms Attempt 3: wait 1000ms (500ms × 2.0) Attempt 4: wait 2000ms (1000ms × 2.0)
The growing intervals give the struggling service breathing room. And because different callers started their retry sequences at slightly different moments, the backoff naturally staggers the waves. Each one arrives smaller and more spread out than the last. The herd thins itself out.
Configuration
The framework exposes all of this through ResilienceProperties:
framework:
resilience:
enabled: true
retry:
max-attempts: 3
wait-duration: 500ms
enable-exponential-backoff: true
exponential-backoff-multiplier: 2.0
The auto-configuration translates these into a Resilience4j RetryConfig:
@Bean
@ConditionalOnMissingBean
public RetryRegistry retryRegistry(final ResilienceProperties properties) {
final ResilienceProperties.RetryProperties retryProps = properties.getRetry();
final RetryConfig.Builder<?> builder = RetryConfig.custom()
.maxAttempts(retryProps.getMaxAttempts())
.retryOnException(e -> !(e instanceof NonRetryableException));
if (retryProps.isEnableExponentialBackoff()) {
builder.intervalFunction(IntervalFunction
.ofExponentialBackoff(
retryProps.getWaitDuration(),
retryProps.getExponentialBackoffMultiplier()));
} else {
builder.waitDuration(retryProps.getWaitDuration());
}
return RetryRegistry.of(builder.build());
}
Two things to note. The retryOnException predicate excludes NonRetryableException — we’ll get to that in a moment. And when enable-exponential-backoff is false, it falls back to a fixed interval between attempts.
NonRetryableException: When to Stop Trying
Not every failure is transient. “Payment declined” will never succeed on retry — the credit card is invalid. “Insufficient stock” is deterministic — the warehouse genuinely doesn’t have the product. Retrying these wastes time, wastes resources, and — if the circuit breaker is counting — burns through your failure budget for no reason.
The framework defines a marker interface:
public interface NonRetryableException {
// Marker interface — business exceptions implement this to skip retry
}
Service exceptions opt in:
public class InsufficientStockException extends RuntimeException
implements NonRetryableException {
public InsufficientStockException(String message) {
super(message);
}
}
public class PaymentDeclinedException extends RuntimeException
implements NonRetryableException {
public PaymentDeclinedException(String message) {
super(message);
}
}
Why a marker interface instead of a base class? Because these exceptions already extend RuntimeException. Java doesn’t have multiple inheritance, but it does have multiple interfaces. The marker lets any exception opt out of retry without changing its class hierarchy.
The retry configuration’s predicate is one line:
.retryOnException(e -> !(e instanceof NonRetryableException))
When retry encounters one of these, it fails immediately. No backoff, no additional attempts. But the circuit breaker still records it as a failure — it still counts toward the failure rate threshold. This is the right behavior. If a service is returning “payment declined” for every single request, something is systematically wrong, and the circuit breaker should trip.
Retry Observability
Resilience4j publishes events for every retry attempt, and the framework hooks into them for structured logging and a custom metric:
public class RetryEventListener {
public RetryEventListener(final RetryRegistry retryRegistry,
final MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
retryRegistry.getAllRetries().forEach(this::registerListeners);
retryRegistry.getEventPublisher().onEntryAdded(
event -> registerListeners(event.getAddedEntry()));
}
private void registerListeners(final Retry retry) {
final var eventPublisher = retry.getEventPublisher();
eventPublisher.onRetry(this::onRetry);
eventPublisher.onSuccess(this::onSuccess);
eventPublisher.onError(this::onError);
eventPublisher.onIgnoredError(this::onIgnoredError);
}
}
Four event types give you the full picture:
| Event | Log Level | What happened |
|---|---|---|
| onRetry | WARN | An attempt failed, trying again |
| onSuccess | INFO | Eventually succeeded |
| onError | ERROR | All retries exhausted |
| onIgnoredError | INFO | Non-retryable, skipped retry |
That last one — onIgnoredError — needed a custom Micrometer counter because Resilience4j’s built-in TaggedRetryMetrics doesn’t track ignored errors:
private void onIgnoredError(final RetryOnIgnoredErrorEvent event) {
logger.info("Non-retryable exception for '{}', skipping retry: {}",
event.getName(), event.getLastThrowable().getMessage());
Counter.builder("framework.resilience.retry.ignored")
.description("Count of non-retryable exceptions that skipped retry")
.tag("name", event.getName())
.register(meterRegistry)
.increment();
}
In practice, the logs tell you a clear story. A transient failure that recovers:
WARN RetryEventListener - Retry attempt #1 for 'payment-processing': Connection refused WARN RetryEventListener - Retry attempt #2 for 'payment-processing': Connection refused INFO RetryEventListener - 'payment-processing' succeeded after 2 attempt(s)
A business exception that gets kicked straight to the dead letter queue:
INFO RetryEventListener - Non-retryable exception for 'payment-processing',
skipping retry: Insufficient funds for amount 15000.00
The ResilienceException Wrapper
When an operation exhausts all retries or gets rejected by an open circuit breaker, the framework wraps the failure in a ResilienceException:
public class ResilienceException extends RuntimeException {
private final String operationName;
public ResilienceException(String message, String operationName, Throwable cause) {
super(message, cause);
this.operationName = operationName;
}
}
The operationName field tells downstream handlers which circuit breaker failed. The dead letter queue integration (Part 9) uses this to classify failures:
if (error instanceof ResilienceException) {
logger.warn("Circuit breaker open, saga step deferred: eventId={}", eventId);
} else {
logger.error("Failed to process event: {}", eventId, error);
}
Auto-Configuration
The whole resilience stack is wired through a single auto-configuration class:
@Configuration
@ConditionalOnClass(CircuitBreakerRegistry.class)
@ConditionalOnProperty(name = "framework.resilience.enabled", matchIfMissing = true)
@EnableConfigurationProperties(ResilienceProperties.class)
public class ResilienceAutoConfiguration {
@Bean @ConditionalOnMissingBean
public CircuitBreakerRegistry circuitBreakerRegistry(ResilienceProperties properties) { ... }
@Bean @ConditionalOnMissingBean
public RetryRegistry retryRegistry(ResilienceProperties properties) { ... }
@Bean @ConditionalOnMissingBean
public ResilientServiceInvoker resilientServiceInvoker(...) { ... }
@Bean @ConditionalOnMissingBean(TaggedCircuitBreakerMetrics.class)
public TaggedCircuitBreakerMetrics taggedCircuitBreakerMetrics(...) { ... }
@Bean @ConditionalOnMissingBean(TaggedRetryMetrics.class)
public TaggedRetryMetrics taggedRetryMetrics(...) { ... }
@Bean @ConditionalOnMissingBean
public RetryEventListener retryEventListener(...) { ... }
}
Three conditionals control activation. @ConditionalOnClass(CircuitBreakerRegistry.class) means the whole thing only activates when Resilience4j is on the classpath — services that don’t include the dependency don’t get any resilience beans. @ConditionalOnProperty(…, matchIfMissing = true) means it’s enabled by default; set framework.resilience.enabled=false to turn it off. And every individual bean is @ConditionalOnMissingBean, so the application can override any piece by defining its own bean.
Six beans total:
- CircuitBreakerRegistry — circuit breaker instances, configured from properties
- RetryRegistry — retry instances with optional exponential backoff
- ResilientServiceInvoker — the decorator that wraps operations
- TaggedCircuitBreakerMetrics — binds circuit breaker metrics to Micrometer
- TaggedRetryMetrics — binds retry metrics to Micrometer
- RetryEventListener — structured logging and the custom ignored-error counter
Per-Instance Tuning
Different saga steps have different tolerance for failure. Stock reservation should be fast and reliable — if it’s failing, something is seriously wrong, and we want the circuit to trip quickly. Payment processing, on the other hand… payment providers are notoriously flaky. You’d rather tolerate a higher failure rate and give the provider more time to sort itself out before you start rejecting everything.
The framework supports per-instance overrides in each service’s application.yml:
framework:
resilience:
enabled: true
circuit-breaker:
failure-rate-threshold: 50
wait-duration-in-open-state: 10s
sliding-window-size: 10
minimum-number-of-calls: 5
permitted-number-of-calls-in-half-open-state: 3
retry:
max-attempts: 3
wait-duration: 500ms
enable-exponential-backoff: true
exponential-backoff-multiplier: 2.0
instances:
inventory-stock-reservation:
circuit-breaker:
failure-rate-threshold: 40
wait-duration-in-open-state: 5s
retry:
max-attempts: 2
payment-processing:
circuit-breaker:
failure-rate-threshold: 60
wait-duration-in-open-state: 15s
retry:
max-attempts: 5
wait-duration: 1s
The instances map lets any named circuit breaker override the defaults:
public CircuitBreakerProperties getCircuitBreakerForInstance(final String name) {
final InstanceProperties instance = instances.get(name);
if (instance != null && instance.getCircuitBreaker() != null) {
return instance.getCircuitBreaker();
}
return circuitBreaker; // Fall back to defaults
}
So in this configuration, inventory-stock-reservation trips at 40% failure rate with a 5-second open state and only 2 retry attempts — stock checks are idempotent and fast, no point dragging things out. payment-processing tolerates 60% failure rate with a 15-second open state and 5 retries starting at 1-second intervals. With exponential backoff, that last attempt waits about 16 seconds. Payment providers get the patience they’ve trained us to give them.
Metrics and Monitoring
The auto-configuration binds circuit breaker and retry metrics to Micrometer, which exports to Prometheus for Grafana dashboards:
Circuit Breaker Metrics
| Metric | Type | Description |
|---|---|---|
| resilience4j_circuitbreaker_state | Gauge | Current state (0=CLOSED, 1=OPEN, 2=HALF_OPEN) |
| resilience4j_circuitbreaker_calls_total | Counter | Total calls by outcome (successful, failed, not_permitted) |
| resilience4j_circuitbreaker_failure_rate | Gauge | Current failure rate percentage |
| resilience4j_circuitbreaker_buffered_calls | Gauge | Calls in sliding window |
Retry Metrics
| Metric | Type | Description |
|---|---|---|
| resilience4j_retry_calls_total | Counter | Total calls by outcome (successful_without_retry, successful_with_retry, failed_with_retry, failed_without_retry) |
| framework.resilience.retry.ignored | Counter | Non-retryable exceptions (tagged by name) |
These feed into Grafana panels for saga health — circuit breaker state timeline showing when breakers trip and recover, retry rate over time where a spike tells you something transient is happening, failure rate broken out by saga step so you can see which one is misbehaving, and the non-retryable exception count that separates business logic failures from infrastructure problems.
Configuration Reference
framework.resilience.*
| Property | Default | Description |
|---|---|---|
| enabled | true | Master toggle for all resilience features |
| circuit-breaker.failure-rate-threshold | 50 | Failure rate (%) to trip the breaker |
| circuit-breaker.wait-duration-in-open-state | 10s | How long to stay open before testing |
| circuit-breaker.sliding-window-size | 10 | Number of calls in the measurement window |
| circuit-breaker.sliding-window-type | COUNT_BASED | COUNT_BASED or TIME_BASED |
| circuit-breaker.minimum-number-of-calls | 5 | Minimum calls before evaluating failure rate |
| circuit-breaker.permitted-number-of-calls-in-half-open-state | 3 | Test calls in half-open state |
| retry.max-attempts | 3 | Maximum retry attempts (including initial) |
| retry.wait-duration | 500ms | Base wait between retries |
| retry.enable-exponential-backoff | true | Use exponential backoff |
| retry.exponential-backoff-multiplier | 2.0 | Backoff multiplier |
| instances.<name>.circuit-breaker.* | (defaults) | Per-instance circuit breaker overrides |
| instances.<name>.retry.* | (defaults) | Per-instance retry overrides |
What’s Next
Circuit breakers and retry handle one category of failure: transient problems during event consumption. The saga listener tries, the call fails, the retry policy kicks in, the circuit breaker keeps the damage from spreading. That covers the consumer side.
But what about the producer side? When EventSourcingController needs to republish an event to the shared cluster and the cluster is temporarily unreachable, the event just… vanishes. No retry. No circuit breaker. Gone.
That’s a different failure mode, and it needs a different mechanism. In Part 8, we add the transactional outbox pattern — a durable buffer between event production and cross-cluster delivery that guarantees no events are lost, even when the shared cluster is down. Then Part 9 closes the loop with dead letter queues and idempotency guards for events that exhaust all retries or arrive more than once.
Next up: The Transactional Outbox Pattern with Hazelcast
Previous: MCP Server for Microservices: AI-Powered Debugging
