Part 8 in the “Building Event-Driven Microservices with Hazelcast” series
Introduction
In Part 7, we added circuit breakers and retry to protect saga listeners from transient failures on the consumer side. That covers what happens when a service receives an event and can’t process it. But we haven’t talked about what happens when the event never leaves the building.
Quick refresher on our dual-instance architecture: each service runs an embedded Hazelcast instance for local Jet pipeline processing and a client connected to the shared cluster for cross-service ITopic communication. After the pipeline processes an event, the EventSourcingController republishes it to the shared cluster so saga listeners in other services can react.
That republish step? It was a fire-and-forget call:
// The old approach — fragile
try {
ITopic<GenericRecord> topic = sharedHazelcast.getTopic(pending.eventType);
topic.publish(pending.eventRecord);
} catch (Exception e) {
logger.warn("Failed to republish event {}: {}", pending.eventType, e.getMessage());
// Event is permanently lost!
}
If the shared cluster is unreachable — network partition, cluster restart, someone tripping over the power cable — the event vanishes. The saga never progresses. Eventually the saga timeout detector marks it as failed, but by then the original event data is gone and there’s nothing to retry.
The Transactional Outbox Pattern fixes this. Instead of publishing directly to the shared cluster, the controller writes the event to a local outbox — an IMap on the embedded Hazelcast instance — and a separate publisher component picks it up and delivers it. If delivery fails, the entry stays in the outbox and gets retried.
Why Direct Publishing Fails
The problem is fundamental. Publishing to an external system (the shared cluster) and completing a local operation (the Jet pipeline) are two separate operations that can’t be made atomic.

The event is safely stored in the local event store and materialized view, but the cross-service notification is lost. You could retry in place, but that blocks the Jet pipeline for all events. You could schedule an async retry, but if the process restarts, that retry state is gone too.
The outbox pattern trades immediate delivery for guaranteed delivery. Write to a durable local store, deliver asynchronously, retry until it works. It’s the standard solution in event-driven architectures for good reason.
Architecture
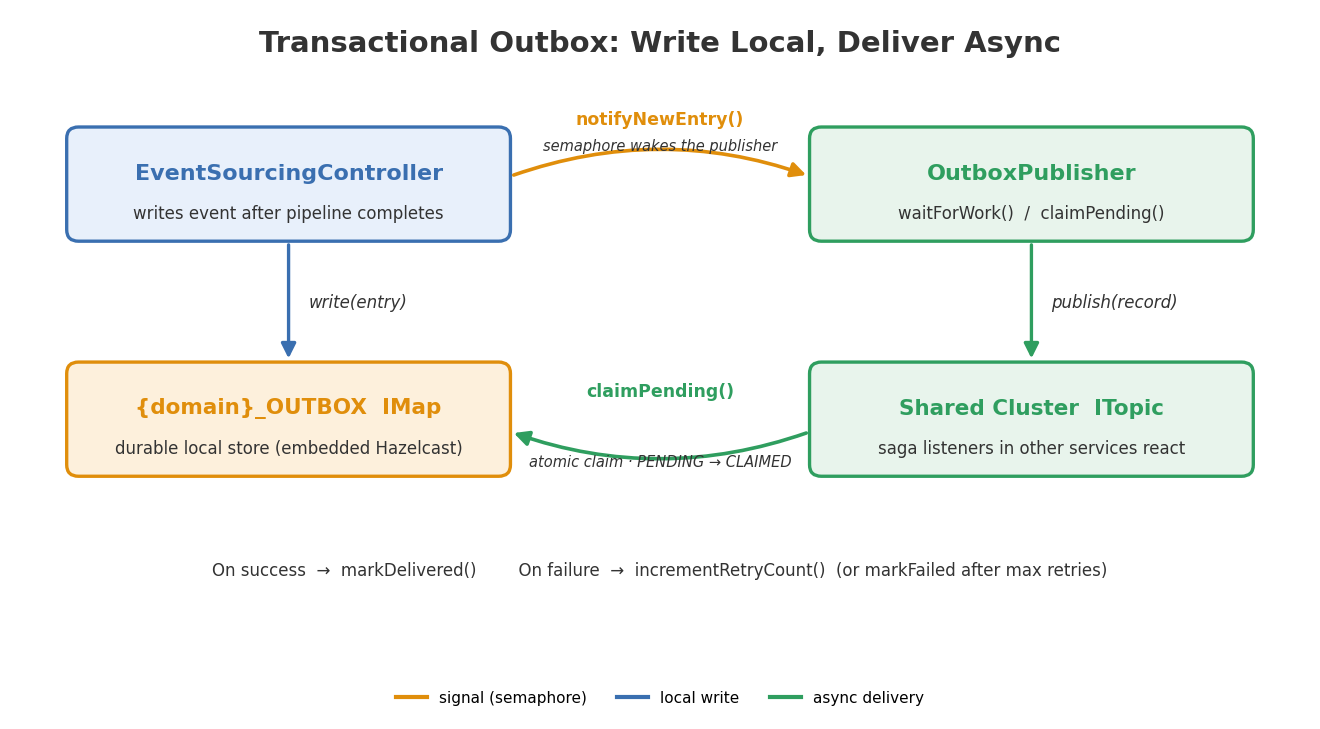
The outbox IMap lives on the embedded Hazelcast instance — the same instance that hosts the event store and materialized views. Writing to it is a local operation. If the embedded instance is up (and it must be, since the pipeline just ran), the outbox write succeeds.
The OutboxEntry
Each outbox entry captures everything needed to deliver the event later:
public class OutboxEntry {
private String eventId; // Matches the domain event's eventId
private String eventType; // ITopic name (e.g., "OrderCreated")
private GenericRecord eventRecord; // The serialized event to publish
private int retryCount; // Delivery attempts so far
private Status status; // PENDING, DELIVERED, or FAILED
private Instant createdAt; // When the entry was created
private Instant lastAttemptAt; // When the last delivery attempt occurred
private String failureReason; // Most recent failure message
public enum Status {
PENDING, // Awaiting delivery
DELIVERED, // Successfully published to shared cluster
FAILED // Permanently failed after max retries
}
}
The eventRecord field is the full GenericRecord that needs to go to the shared cluster’s ITopic — same record the Jet pipeline produces, complete with saga metadata like sagaId and correlationId.
OutboxStore: The Interface
Six methods covering the full lifecycle:
public interface OutboxStore {
void write(OutboxEntry entry);
List<OutboxEntry> pollPending(int maxBatchSize);
void markDelivered(String eventId);
void markFailed(String eventId, String reason);
void incrementRetryCount(String eventId, String failureReason);
long pendingCount();
}
Provider-agnostic. The Hazelcast implementation uses an IMap, but the interface could just as easily sit in front of a database table.
HazelcastOutboxStore
The Hazelcast implementation stores entries as Compact-serialized GenericRecord values in an IMap:
public class HazelcastOutboxStore implements OutboxStore {
private static final String SCHEMA_NAME = "OutboxEntry";
private final IMap<String, GenericRecord> outboxMap;
public HazelcastOutboxStore(HazelcastInstance hazelcast, MeterRegistry meterRegistry) {
this.outboxMap = hazelcast.getMap(DEFAULT_MAP_NAME);
}
}
You might wonder why we’re using GenericRecord instead of storing OutboxEntry Java objects directly. The problem is that OutboxEntry has an Instant field and a nested GenericRecord — neither of which Hazelcast’s zero-config Compact serialization can handle. We’d need a custom CompactSerializer registered on every Hazelcast instance configuration. Instead, we convert at the boundary:
static GenericRecord toRecord(final OutboxEntry entry) {
return GenericRecordBuilder.compact(SCHEMA_NAME)
.setString("eventId", entry.getEventId())
.setString("eventType", entry.getEventType())
.setGenericRecord("eventRecord", entry.getEventRecord())
.setInt32("retryCount", entry.getRetryCount())
.setString("status", entry.getStatus().name())
.setInt64("createdAt", entry.getCreatedAt().toEpochMilli())
.setNullableInt64("lastAttemptAt",
entry.getLastAttemptAt() != null
? entry.getLastAttemptAt().toEpochMilli() : null)
.setString("failureReason", entry.getFailureReason())
.build();
}
A few things going on here. Instant becomes int64 epoch millis — compact, sortable, unambiguous. lastAttemptAt uses setNullableInt64 because it’s null until the first delivery attempt. The nested eventRecord uses setGenericRecord, which Compact handles natively. And status is stored as the enum name string, which makes it readable in Management Center and queryable with Predicates.equal().
Polling uses a Hazelcast predicate to filter by status, sorted by creation time so the oldest entries are delivered first:
@Override
public List<OutboxEntry> pollPending(final int maxBatchSize) {
final Collection<GenericRecord> pending = outboxMap.values(
Predicates.equal("status", OutboxEntry.Status.PENDING.name()));
return pending.stream()
.map(HazelcastOutboxStore::fromRecord)
.sorted(Comparator.comparing(OutboxEntry::getCreatedAt))
.limit(maxBatchSize)
.collect(Collectors.toList());
}
The OutboxPublisher
The publisher bridges the outbox and the shared cluster. The obvious approach is to poll on a fixed interval — once per second, say — but that adds latency we don’t need. We know exactly when a new entry arrives.
Event-Driven Wake-Up
The publisher uses a Semaphore to sleep until someone signals it:
public class OutboxPublisher {
private final Semaphore wakeUp = new Semaphore(0);
public void notifyNewEntry() {
// Release at most 1 permit — avoids unbounded accumulation
if (wakeUp.availablePermits() == 0) {
wakeUp.release();
}
}
public boolean waitForWork() {
try {
return wakeUp.tryAcquire(
properties.getPollInterval().toMillis(),
TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
}
}
}
When the EventSourcingController writes an outbox entry, it calls notifyNewEntry() right after. The publisher wakes up, claims all pending entries, delivers them. Under normal conditions, the time from event creation to shared-cluster delivery is sub-millisecond.
The poll interval (default 1 second) is the safety net. If a signal gets missed — maybe the publisher was busy with a previous batch — the timeout ensures nothing sits around for too long.
This is a JVM-local semaphore, not a distributed one. That’s fine. When the service scales to multiple replicas with per-service clustering (ADR 013), each replica has its own publisher. The semaphore wakes the local publisher instantly for locally-written events. Events written by other replicas get picked up within the poll interval. The actual coordination — preventing two replicas from delivering the same event — happens in claimPending() via an atomic ClaimEntryProcessor on the IMap.
The Publish Loop
public void publishPendingEntries() {
if (sharedHazelcast == null) {
if (!noSharedClusterWarningLogged) {
logger.warn("No shared Hazelcast instance — outbox delivery skipped");
noSharedClusterWarningLogged = true;
}
return;
}
List<OutboxEntry> claimed = outboxStore.claimPending(
properties.getMaxBatchSize(), memberUuid);
if (claimed.isEmpty()) {
return;
}
for (OutboxEntry entry : claimed) {
try {
ITopic<GenericRecord> topic = sharedHazelcast.getTopic(entry.getEventType());
topic.publish(entry.getEventRecord());
outboxStore.markDelivered(entry.getEventId());
} catch (Exception e) {
if (entry.getRetryCount() + 1 >= properties.getMaxRetries()) {
outboxStore.markFailed(entry.getEventId(),
"Max retries exceeded: " + e.getMessage());
} else {
outboxStore.incrementRetryCount(entry.getEventId(), e.getMessage());
}
}
}
}
Note claimPending rather than pollPending. The claiming mechanism uses an EntryProcessor to atomically transition entries from PENDING to CLAIMED, tagging them with the claiming member’s UUID. This prevents two publisher instances from delivering the same event — important once you’re running multiple replicas.
When no shared cluster is configured (single-node dev mode), the publisher logs one warning and stops trying. Events pile up as PENDING in the outbox. They’ll drain as soon as a shared cluster appears.
Retry escalation is per-entry:
Attempt 1: fails → incrementRetryCount (retryCount=1) Attempt 2: fails → incrementRetryCount (retryCount=2) ... Attempt 5: fails → markFailed (retryCount=5 >= maxRetries=5)
Once marked FAILED, the entry stops showing up in claim results. The failure reason is preserved for debugging.
Scheduling
OutboxAutoConfiguration hooks the publisher into Spring’s task scheduler:
@EnableScheduling
public class OutboxAutoConfiguration implements SchedulingConfigurer {
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
taskRegistrar.addFixedDelayTask(() -> {
outboxPublisher.waitForWork(); // blocks until signaled or timeout
outboxPublisher.publishPendingEntries();
}, 1); // 1ms loop delay — actual timing controlled by semaphore
}
}
The 1ms fixed delay means the loop restarts almost immediately after each cycle, but waitForWork() controls the actual pacing. The thread blocks on the semaphore until either a permit is released or the poll interval elapses. Near-instant delivery under normal load, guaranteed pickup if a signal is missed.
Integration with EventSourcingController
The controller’s republishToSharedCluster now checks for an outbox store first:
private void republishToSharedCluster(PendingCompletion<K> pending) {
if (sharedHazelcast == null || pending.eventRecord == null || pending.eventType == null) {
return;
}
if (outboxStore != null) {
OutboxEntry entry = new OutboxEntry(
pending.completionInfo.getEventId(),
pending.eventType,
pending.eventRecord
);
outboxStore.write(entry);
if (outboxPublisher != null) {
outboxPublisher.notifyNewEntry();
}
} else {
// Legacy direct publish (when outbox is disabled)
try {
ITopic<GenericRecord> topic = sharedHazelcast.getTopic(pending.eventType);
topic.publish(pending.eventRecord);
} catch (Exception e) {
logger.warn("Failed to republish event {}: {}", pending.eventType, e.getMessage());
}
}
}
Fully backward compatible. When outboxStore is injected, events go through the durable path. When it’s null, you get the old fire-and-forget behavior. The OutboxStore is wired through each service’s config as an optional dependency:
@Bean
public EventSourcingController<Order, String, DomainEvent<Order, String>> orderController(
HazelcastInstance hazelcastInstance,
@Qualifier("hazelcastClient") HazelcastInstance hazelcastClient,
@Autowired(required = false) OutboxStore outboxStore,
...) {
return EventSourcingController.builder()
.hazelcast(hazelcastInstance)
.sharedHazelcast(hazelcastClient)
.outboxStore(outboxStore)
.build();
}
Delivery Guarantees
The outbox provides at-least-once delivery. If the publisher crashes after publishing to the ITopic but before calling markDelivered(), the next cycle picks up the same entry and delivers it again. Events are never lost as long as the embedded Hazelcast instance’s IMap data is intact.
At-least-once means consumers may see duplicates. That’s where the Idempotency Guard from Part 9 comes in — it deduplicates on the consumer side, complementing the outbox’s guaranteed delivery.
As for ordering: events for the same aggregate are written to the outbox in sequence order (the Jet pipeline processes them sequentially), and claimPending sorts by createdAt. But if two events are pending simultaneously and the first one fails while the second succeeds, they’ll arrive out of order. For our saga use case that’s acceptable — each step is identified by sagaId and eventType, and the saga state machine handles duplicates and out-of-order delivery.
Configuration
framework.outbox.*
| Property | Default | Description |
|---|---|---|
| enabled | true | Master toggle for the outbox pattern |
| poll-interval | 1000 (ms) | Fallback interval if signal is missed |
| max-batch-size | 50 | Maximum entries per poll cycle |
| max-retries | 5 | Delivery attempts before permanent failure |
| entry-ttl | 24h | How long DELIVERED entries survive in the map |
Metrics
| Metric | Type | Description |
|---|---|---|
| outbox.entries.written | Counter | Events written to the outbox |
| outbox.entries.delivered | Counter | Events delivered to shared cluster |
| outbox.entries.failed | Counter | Events permanently failed |
| outbox.publish.duration | Timer | Time per publish cycle |
To disable the outbox and use direct publishing:
framework:
outbox:
enabled: false
What’s Next
The outbox guarantees events reach the shared cluster. But what happens when they get there and the consumer can’t process them? The consumer might crash, the business logic might throw, the circuit breaker might be open.
In Part 9, we add two patterns that work together: a Dead Letter Queue that captures events that fail consumer-side processing, and an Idempotency Guard that prevents duplicate processing — the natural flip side of at-least-once delivery.
Next up: Dead Letter Queues and Idempotency
Previous: Circuit Breakers and Retry: Resilient Hazelcast Sagas
