Part 3 in the “Building Event-Driven Microservices with Hazelcast” series
Introduction
We’ve established that events are the source of truth (Part 1) and built a Jet pipeline to process them (Part 2). But we’ve been dancing around a question that anyone who’s thought about event sourcing for more than five minutes will ask:
If everything is stored as a sequence of events, how do you actually query anything?
The Problem with Raw Events
The naive answer is “replay them.” Want the current state of customer 123? Walk through every event that ever happened to customer 123 and apply them in order:
public Customer getCustomer(String customerId) {
List<Event> events = eventStore.getEventsForKey(customerId);
Customer customer = null;
for (Event event : events) {
customer = event.apply(customer);
}
return customer;
}
This works. It’s also terrible. A customer with 10 events takes 10x longer to load than a brand-new customer with 1. A customer who’s been active for three years and has 1,000 events? Good luck serving that from an API endpoint with a latency SLA.
You need O(1) lookups, not O(n) replays on every GET request.
CQRS: The Pattern You Don’t Get to Opt Out Of
This is where event sourcing stops being a standalone pattern and starts demanding an architectural partner.
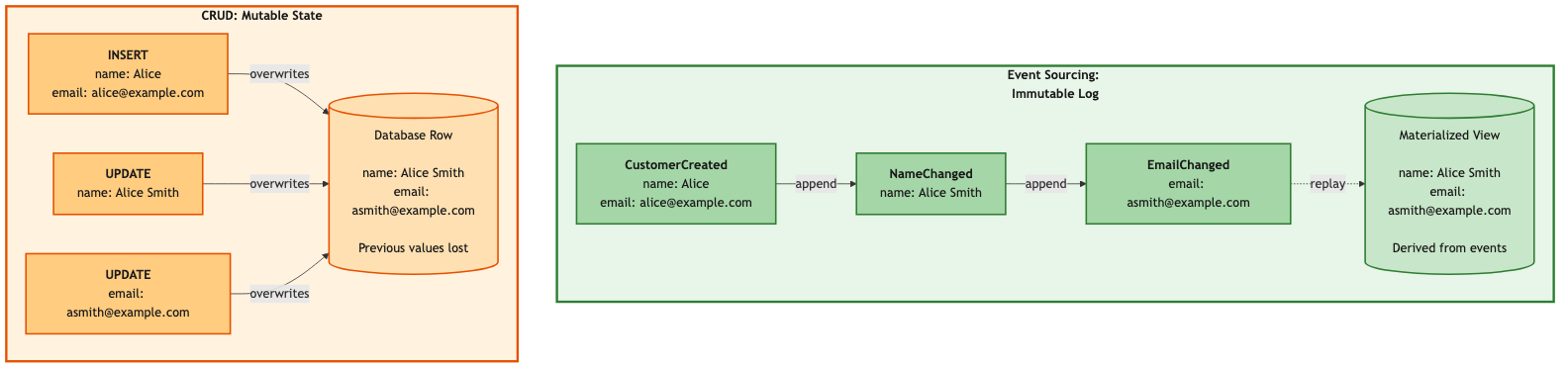
In a CRUD system, one table does everything. You INSERT into it, UPDATE it, and SELECT from it. The read model and the write model are the same thing — a row in a database. Simple.
Event sourcing breaks that. Your write model is an append-only event log. Great for durability, great for auditing, terrible for queries. You can’t SELECT a customer’s current address from a log of every change that’s ever happened to them. Not efficiently, anyway.
So you need a separate read model. A structure that’s optimized for the queries your application actually needs. This separation — commands go to the write model, queries go to the read model — is CQRS: Command Query Responsibility Segregation.
We didn’t choose CQRS because it appeared on a list of architecture buzzwords. Event sourcing forced us into it. Once your source of truth is an event log, you need a separate read path. There’s no way around it.
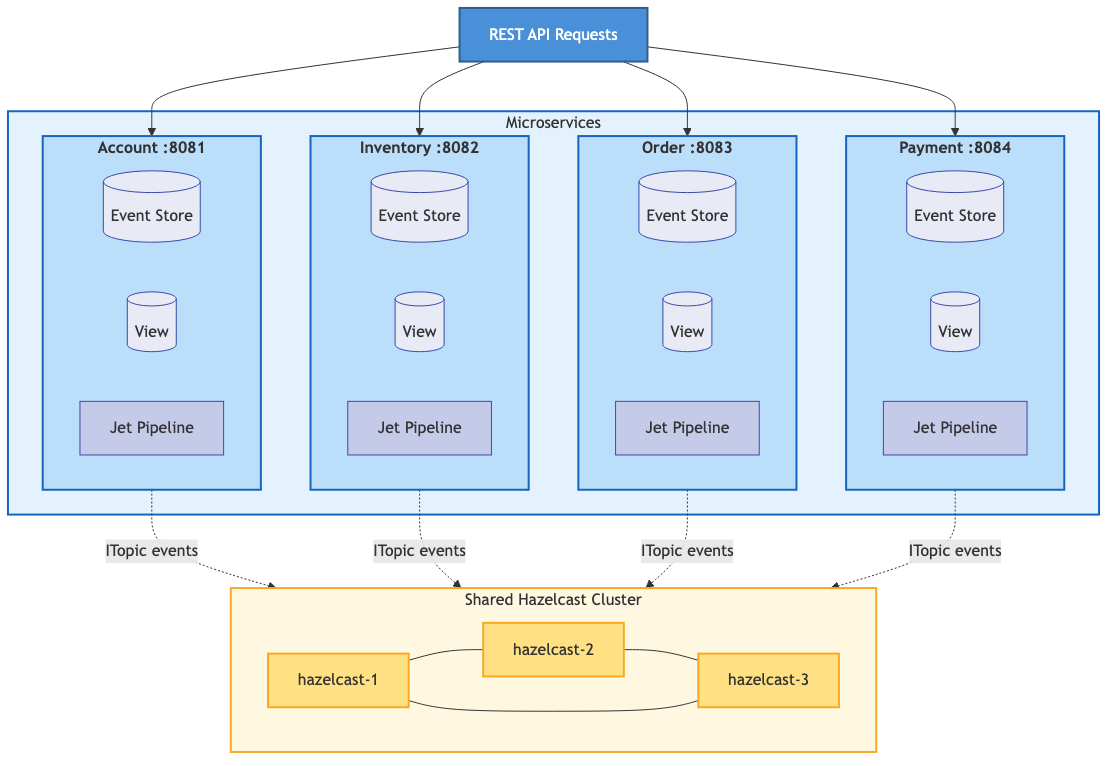
Now, CQRS is a general pattern. The read model could be a relational database you project events into for complex SQL queries. It could be Elasticsearch for full-text search, or a data warehouse for analytics. In our framework, we project into Hazelcast IMaps — materialized views that update in real-time as events flow through the Jet pipeline. The IMap gives us sub-millisecond lookups and keeps the read model co-located with the processing engine. No network hop, no separate database to manage.
Materialized views are our implementation of the read side of CQRS.
What is a Materialized View?
A materialized view is a pre-computed projection. Instead of computing state on every query, you compute it once — when the event is processed in Stage 4 of the pipeline — and store the result. Queries just look up the stored result. In event sourcing literature, the component responsible for maintaining these projections is sometimes called a projection engine. In our framework, that’s the Jet pipeline from Part 2.
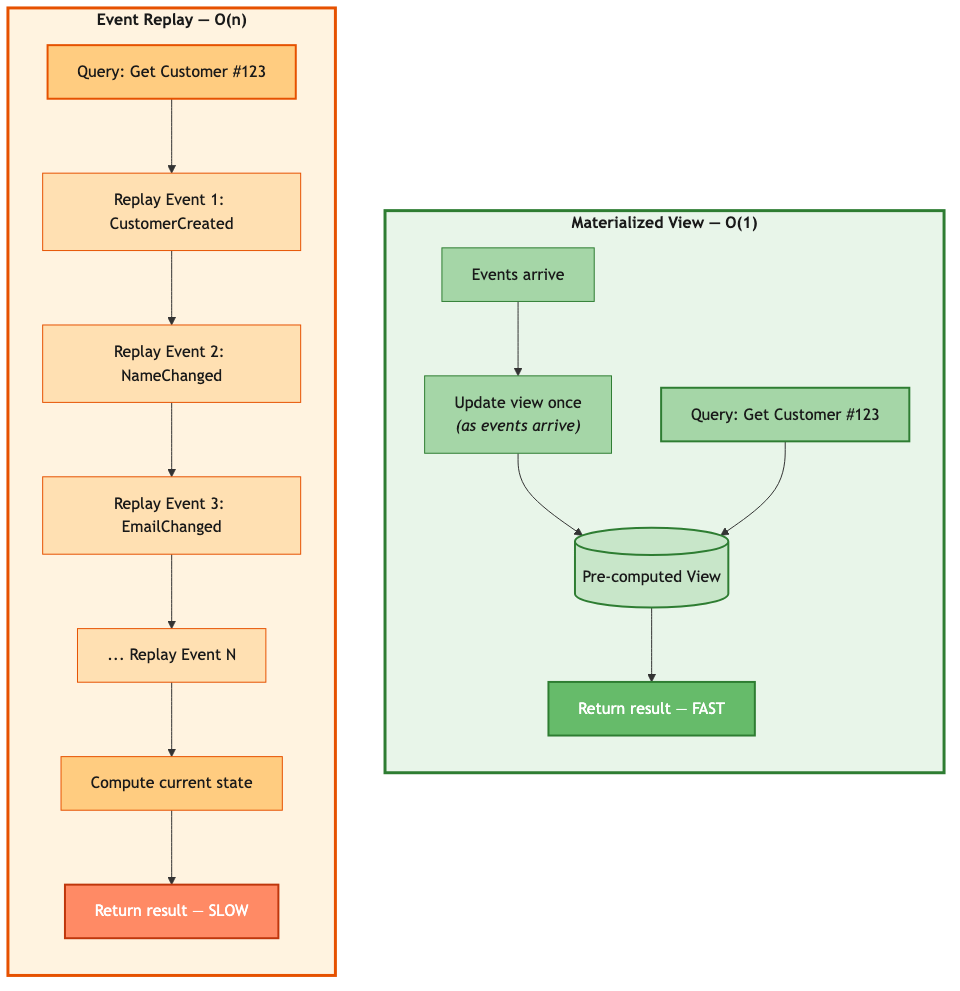
The write path pays the cost once. Every subsequent read is free. The more reads you have per write — and most systems are read-heavy — the bigger the win.
The ViewStore
The HazelcastViewStore wraps an IMap:
public class HazelcastViewStore<K> {
private final IMap<K, GenericRecord> viewMap;
private final String viewName;
public HazelcastViewStore(HazelcastInstance hazelcast, String viewName) {
this.viewName = viewName + "_VIEW";
this.viewMap = hazelcast.getMap(this.viewName);
}
public Optional<GenericRecord> get(K key) {
return Optional.ofNullable(viewMap.get(key));
}
public void put(K key, GenericRecord value) {
viewMap.set(key, value);
}
public void remove(K key) {
viewMap.delete(key);
}
public GenericRecord executeOnKey(K key,
EntryProcessor<K, GenericRecord, GenericRecord> processor) {
return viewMap.executeOnKey(key, processor);
}
}
We use GenericRecord for the values — Hazelcast’s schema-flexible format that doesn’t require Java classes on the cluster. The executeOnKey method gives us atomic updates through Hazelcast’s EntryProcessor. As we discussed in Part 2, the EntryProcessor runs on the partition thread for that key — the same single-threaded-per-partition model that makes our pipeline ordering work. It reads current state, applies the change, and writes the result, all on one thread with no possibility of a concurrent modification. Atomic by architecture, not by locking.
The ViewUpdater
The ViewUpdater is the abstract class that each domain implements. It defines two things: how to extract the key from an event, and how to apply the event to produce new state.
public abstract class ViewUpdater<K> implements Serializable {
protected final transient HazelcastViewStore<K> viewStore;
protected abstract K extractKey(GenericRecord eventRecord);
protected abstract GenericRecord applyEvent(
GenericRecord eventRecord,
GenericRecord currentState);
public GenericRecord updateDirect(GenericRecord eventRecord) {
K key = extractKey(eventRecord);
if (key == null) {
logger.warn("Could not extract key from event");
return null;
}
GenericRecord currentState = viewStore.get(key).orElse(null);
GenericRecord updatedState = applyEvent(eventRecord, currentState);
if (updatedState != null) {
viewStore.put(key, updatedState);
} else if (currentState != null) {
viewStore.remove(key);
}
return updatedState;
}
}
Returning null from applyEvent is the deletion convention. The updater removes the entry from the view. Everything else either creates a new entry or updates an existing one.
Example: Customer View
Here’s what a concrete implementation looks like:
public class CustomerViewUpdater extends ViewUpdater<String> {
public static final String VIEW_NAME = "Customer";
public CustomerViewUpdater(HazelcastViewStore<String> viewStore) {
super(viewStore);
}
@Override
protected String extractKey(GenericRecord eventRecord) {
return eventRecord.getString("key");
}
@Override
protected GenericRecord applyEvent(GenericRecord event, GenericRecord current) {
String eventType = getEventType(event);
return switch (eventType) {
case "CustomerCreated" -> createCustomer(event);
case "CustomerUpdated" -> updateCustomer(event, current);
case "CustomerStatusChanged" -> changeStatus(event, current);
case "CustomerDeleted" -> null;
default -> {
logger.debug("Unknown event type: {}", eventType);
yield current;
}
};
}
private GenericRecord createCustomer(GenericRecord event) {
Instant now = Instant.now();
return GenericRecordBuilder.compact(VIEW_NAME)
.setString("customerId", event.getString("key"))
.setString("email", event.getString("email"))
.setString("name", event.getString("name"))
.setString("address", event.getString("address"))
.setString("phone", getStringField(event, "phone"))
.setString("status", "ACTIVE")
.setInt64("createdAt", now.toEpochMilli())
.setInt64("updatedAt", now.toEpochMilli())
.build();
}
private GenericRecord updateCustomer(GenericRecord event, GenericRecord current) {
if (current == null) {
logger.warn("Update event for non-existent customer: {}",
event.getString("key"));
return null;
}
return GenericRecordBuilder.compact(VIEW_NAME)
.setString("customerId", current.getString("customerId"))
.setString("email", coalesce(event.getString("email"),
current.getString("email")))
.setString("name", coalesce(event.getString("name"),
current.getString("name")))
.setString("address", coalesce(event.getString("address"),
current.getString("address")))
.setString("phone", coalesce(getStringField(event, "phone"),
current.getString("phone")))
.setString("status", current.getString("status"))
.setInt64("createdAt", current.getInt64("createdAt"))
.setInt64("updatedAt", Instant.now().toEpochMilli())
.build();
}
private GenericRecord changeStatus(GenericRecord event, GenericRecord current) {
if (current == null) return null;
return GenericRecordBuilder.compact(VIEW_NAME)
.setString("customerId", current.getString("customerId"))
.setString("email", current.getString("email"))
.setString("name", current.getString("name"))
.setString("address", current.getString("address"))
.setString("phone", current.getString("phone"))
.setString("status", event.getString("newStatus"))
.setInt64("createdAt", current.getInt64("createdAt"))
.setInt64("updatedAt", Instant.now().toEpochMilli())
.build();
}
private String coalesce(String newValue, String currentValue) {
return newValue != null ? newValue : currentValue;
}
}
The coalesce pattern in updateCustomer handles partial updates — if the event only includes a new email but not a new name, we keep the existing name. The updatedAt timestamp always advances, which is useful for staleness checks later.
Cross-Service Views: Denormalization Without the Guilt
This is where materialized views get genuinely powerful.
Consider displaying an order. The raw order data has a customer ID and product IDs, but no names, no emails, no SKUs. To show a complete order in the UI, you need data that lives in two other services.
The traditional approach:
Order order = orderRepository.findById(orderId);
Customer customer = accountService.getCustomer(order.getCustomerId()); // HTTP call
for (LineItem item : order.getItems()) {
Product product = inventoryService.getProduct(item.getProductId()); // HTTP call
item.setProductName(product.getName());
}
Three services involved at query time. If Account is slow, your order page is slow. If Inventory is down, your order page is broken. And you’ve just coupled three services together at runtime, which is exactly what microservices were supposed to prevent.
With event sourcing, you build an enriched view that bakes in the data from other services at write time:
public class EnrichedOrderViewUpdater extends ViewUpdater<String> {
private final IMap<String, GenericRecord> customerView;
private final IMap<String, GenericRecord> productView;
@Override
protected GenericRecord applyEvent(GenericRecord event, GenericRecord current) {
String eventType = getEventType(event);
if ("OrderCreated".equals(eventType)) {
return createEnrichedOrder(event);
}
return current;
}
private GenericRecord createEnrichedOrder(GenericRecord event) {
String customerId = event.getString("customerId");
// Look up customer from local view — no HTTP call
GenericRecord customer = customerView.get(customerId);
String customerName = customer != null ?
customer.getString("name") : "Unknown";
String customerEmail = customer != null ?
customer.getString("email") : "";
List<GenericRecord> enrichedItems = new ArrayList<>();
// ... iterate through items, look up products from productView
return GenericRecordBuilder.compact("EnrichedOrder")
.setString("orderId", event.getString("key"))
.setString("customerId", customerId)
.setString("customerName", customerName)
.setString("customerEmail", customerEmail)
.setArrayOfGenericRecord("lineItems",
enrichedItems.toArray(new GenericRecord[0]))
.setString("status", "PENDING")
.build();
}
}
The result is a single IMap entry with everything you need:
{
"orderId": "order-123",
"customerId": "cust-456",
"customerName": "Alice Smith",
"customerEmail": "alice@example.com",
"lineItems": [
{
"productId": "prod-789",
"productName": "Gaming Laptop",
"sku": "LAPTOP-001",
"quantity": 2,
"unitPrice": 49.99
}
],
"status": "PENDING"
}
One lookup. Zero service calls. Works if Account and Inventory are both down for maintenance.
If you’re from a relational database background, denormalization feels wrong — it violates third normal form, it duplicates data, your DBA would glare at you. But in an event-sourced system, the events are the normalized source of truth. Views are disposable projections. Denormalize all you want. If Alice changes her name, the CustomerUpdated event flows through, and you can update the enriched order view to reflect it. Or not, depending on whether you care — the order was placed when she was “Alice Smith,” and that’s what the event says.
View Rebuilding
One of the benefits we mentioned in Part 1 — and it’s worth seeing in practice. Found a bug in your view update logic? Fix the code, clear the view, replay the events:
public <D extends DomainObject<K>, E extends DomainEvent<D, K>> long rebuild(
EventStore<D, K, E> eventStore) {
logger.info("Starting view rebuild for {} from {}",
viewStore.getViewName(), eventStore.getStoreName());
viewStore.clear();
AtomicLong count = new AtomicLong(0);
eventStore.replayAll(eventRecord -> {
updateDirect(eventRecord);
count.incrementAndGet();
});
logger.info("Rebuild complete. Processed {} events", count.get());
return count.get();
}
Same mechanism handles schema migrations, new view types (write a new ViewUpdater, replay existing events — instant backfill), and disaster recovery. With CRUD, corrupted data is permanently corrupted. With event sourcing, the correct data is always recoverable from the event stream.
View Patterns
Not every view is a 1:1 entity projection. Here are the patterns we use:
Entity View — one entry per domain object. Customer events produce one Customer view entry, keyed by customer ID. This is the default.
Lookup View — index by an alternate key. A Customer-by-Email view maps email → customerId, so you can find a customer by email without scanning. When a customer changes their email, the old entry gets deleted and a new one created.
Summary View — aggregate across entities. A Customer Order Summary view tracks customerId → { totalOrders, totalSpent }, incrementing on OrderCreated and decrementing on OrderCancelled.
Enriched View — denormalization across services, as we just covered. Order events plus customer and product data produce a self-contained order view.
Time-Series View — track changes over time. Daily inventory snapshots keyed by date + productId, updated by stock reservation and release events.
You can maintain as many views as you need from the same event stream. They’re independent — a bug in one doesn’t affect the others, and each can be rebuilt separately.
Handling View Staleness
Views are updated asynchronously by the pipeline. There’s a brief window — usually measured in milliseconds — where the view might not reflect the very latest event. Three ways to deal with it:
Accept it. For most reads, a few milliseconds of staleness is fine. Just read the view.
Customer customer = customerView.get(customerId);
Wait for it. When you need to read your own writes — like returning a newly created customer right after creating them — wait for the pipeline to complete:
CompletableFuture<EventCompletion> future = controller.handleEvent(event, correlationId); future.join(); // Now the view is guaranteed to reflect this event Customer customer = customerView.get(customerId);
Check it. Include a version or timestamp and verify the view is current enough:
long expectedVersion = event.getTimestamp().toEpochMilli();
Customer customer = customerView.get(customerId);
if (customer.getUpdatedAt() < expectedVersion) {
// View not yet updated — wait or return the event data directly
}
Our framework’s handleEvent returns a CompletableFuture specifically to make the “wait for it” path easy. Most API endpoints use it.
Performance
Materialized view reads are IMap lookups. On a single laptop (M4 MacBook Pro, 16GB, Docker Compose):
| Operation | Latency |
|---|---|
| View read (local partition) | < 0.1ms |
| View read (remote partition) | < 0.5ms |
| View read (near cache) | < 0.01ms |
| View update (pipeline Stage 4) | < 1ms |
For views that get read far more often than they’re written — which is most of them — near cache is worth enabling:
hazelcast:
map:
Customer_VIEW:
near-cache:
name: customer-near-cache
time-to-live-seconds: 30
max-idle-seconds: 10
eviction:
eviction-policy: LRU
max-size-policy: ENTRY_COUNT
size: 10000
This caches view entries locally on the client side. Reads drop to microseconds. The TTL ensures stale entries get refreshed, and LRU eviction keeps memory bounded.
Predefined Queries vs. Ad-Hoc Access
Everything we’ve built so far serves predefined query patterns — get customer by ID, get enriched order, look up product stock. The services expose exactly the queries their API needs, and those queries are fast because the views are designed for them.
Sooner or later, though, someone from the business side is going to want more. “Show me all orders over $500 in the last 30 days.” “Which customers changed their address this quarter?” Hazelcast supports SQL queries against IMaps — through Management Center, the command-line client, or third-party tools like DBeaver. The capability is there.
But I wouldn’t be eager to have my production throughput impacted by someone’s exploratory query with a broad predicate scanning thousands of entries. An analyst’s ad-hoc join returning ten thousand rows is a very different workload than a targeted key lookup, and it can absolutely affect the latency your customers see.
If you want to give analysts this kind of access — and there are good reasons to — consider WAN replication (a Hazelcast Enterprise feature) to duplicate your IMap data into a secondary cluster dedicated to analytics. Analysts query to their heart’s content; production stays untouched. This is really just CQRS taken one step further. We already separated the write model (events) from the operational read model (views). WAN replication separates the operational read model from the analytical read model. Same principle, another level of isolation.
Practical Advice
Keep your views focused. A CustomerView for profile queries, a CustomerByEmailView for authentication, a CustomerOrderSummary for order history. Don’t build a CustomerEverythingView that tries to serve every possible query pattern — it’ll be expensive to update and awkward to query.
Document what events feed each view. When someone asks “why does the order view show the wrong customer name?” you want to be able to trace it: “The order view is updated by OrderCreated events, and it reads customer data from the Customer view at enrichment time. If the customer name changed after the order was created, the order view still shows the name at order time.”
Handle missing data gracefully. When the enriched order view looks up a customer and gets null — maybe the customer was deleted, maybe the customer event hasn’t propagated yet — don’t crash. Use a sensible default:
GenericRecord customer = customerView.get(customerId);
String customerName = customer != null ?
customer.getString("name") : "Customer " + customerId;
And think about rebuild cost before your event history gets large. Replaying a million events to rebuild a view takes time. Strategies include periodic snapshots (save the view state and replay only from the snapshot forward), incremental rebuilds (track the last processed event sequence), and parallel rebuilds for independent views.
That covers the read side of CQRS — how we turn an append-only event stream into fast, queryable state. The views are disposable, rebuildable, and independent. Denormalization is a feature, not a compromise. And the whole thing runs at IMap speed because the read model lives in the same platform as the processing engine.
Next we’ll move from a single service to many. When a business operation has to update state in two or three different services and any one of them can fail, two-phase commit is off the table and you need a different answer. That’s the saga pattern.
Next up: The Saga Pattern for Distributed Transactions