Part 1 in the “Building Event-Driven Microservices with Hazelcast” series
Introduction
Here’s something that should bother you more than it probably does: every time you run an UPDATE statement against a database, you’re destroying information.
UPDATE customers SET address = '456 Oak Ave' WHERE id = 'cust-123';
That customer used to live at 123 Main St. Now they don’t. And you have no idea that 123 Main St ever existed, because you just overwrote it. The old address is gone. The audit trail is gone. If someone asks “where did this customer live six months ago?” you shrug and check if maybe somebody logged it somewhere.
We’ve been building systems like this for decades, and honestly, it mostly works. Until it doesn’t. Until you need to debug a production issue and you can’t figure out what sequence of changes got the system into this state. Until compliance asks for a history of every change to customer PII. Until Service A goes down and takes Services B, C, and D with it because they all need to call A synchronously to get data they should already have.
Event sourcing flips this model. Instead of storing current state, you store the sequence of events that produced it. The current state becomes something you derive — a view that you can rebuild from events at any time.
In this post, we’ll look at how to implement event sourcing with Hazelcast, which turns out to be a remarkably good fit for this pattern. Fast writes for the event stream, real-time processing with Jet pipelines, and sub-millisecond reads from materialized views — it’s basically the whole event sourcing infrastructure in one platform.
What is Event Sourcing?
The core idea is simple enough to state in three lines:
- Every state change is captured as an immutable event
- Current state is computed by replaying those events
- The complete history is preserved forever
That third point is the one that makes people nervous. “Forever? Really? Every event?” Yes. That’s the deal. And it turns out to be the source of most of the pattern’s power.
A Quick Example
Take that customer we just destroyed with an UPDATE. In event sourcing, there is no UPDATE. There are only events:
Event 1: CustomerCreatedEvent { customerId: 'cust-123', address: '123 Main St' }
Event 2: CustomerAddressChangedEvent { customerId: 'cust-123', address: '456 Oak Ave' }
The current address is still 456 Oak Ave. But the old address is still there in Event 1. Nothing was overwritten. Nothing was lost. You can reconstruct the customer’s state at any point in time by replaying events up to that moment.
Why Event Sourcing?
I get it — the first time you encounter event sourcing, the reaction is usually something like “you want me to store every event forever instead of just updating a row? That sounds like a lot more work.” And honestly, it does feel unfamiliar, and unfamiliar feels like ick. You need a compelling reason to push past that.
There are several.
Microservices Need Decoupling, and Events Actually Deliver It
The whole pitch for microservices is services that can be developed, deployed, and scaled independently. Beautiful theory. In practice, the independence evaporates the moment one service makes a synchronous REST call to another to get data it needs.
Think about it. The Account service goes down — does the Order service go down with it? If Order is making HTTP calls to Account to look up customer names, then yes. Probably yes. You’ve built yourself a distributed monolith: all the operational complexity of microservices with none of the resilience benefits. Congratulations.
Event sourcing solves this at an architectural level, not with duct tape. When a customer is created, the Account service publishes a CustomerCreatedEvent. The Order service subscribes to those events and builds its own local materialized view of customer data. No HTTP call. No dependency on Account being up. No shared database.
If Account goes down for maintenance on a Tuesday afternoon, Order keeps running. It already has the customer data it needs. The services are actually decoupled — not just deployed to separate containers while secretly depending on each other for every request.
Events Capture What Actually Happened
Here’s a distinction that seems pedantic until it saves you during a production incident. A database transaction log records what changed:
UPDATE customers SET address = '456 Oak Ave' WHERE id = 'cust-123';
A domain event records what happened in business terms:
CustomerMovedEvent { customerId: 'cust-123', previousAddress: '123 Main St',
newAddress: '456 Oak Ave', reason: 'RELOCATION' }
The transaction log tells you a column changed. The domain event tells you a customer moved, where they moved from, and why. That business context gets captured once, at the moment it happens, and it’s preserved forever.
When someone asks “why did this order ship to the wrong address?” you can trace the exact sequence: here’s when the customer moved, here’s the order that was placed two hours before the address change propagated, here’s why the old address was used. With CRUD, you’d be spelunking through application logs and hoping somebody thought to log the right thing.
Event Streams Are AI-Ready Data
This one has been sneaking up on us.
An event-sourced system doesn’t just store what the world looks like right now. It stores how it got there — a sequence of business actions, ordered in time, with context attached. That turns out to be exactly the kind of data that AI systems are hungry for.
Look at what an AI agent sees when it queries a traditional database: customer has address X, has ordered Y items, has a balance of Z. A flat snapshot. Static. Not much to work with beyond simple lookups.
Now look at what it sees in an event stream:
CustomerCreatedEvent → new customer in Seattle ProductViewedEvent (×12) → browsed camping gear heavily CartUpdatedEvent (×4) → added/removed items, compared prices OrderPlacedEvent → bought mid-range tent, not the premium one CustomerMovedEvent → relocated to Denver ProductViewedEvent (×8) → browsing ski equipment
That’s a behavioral narrative. Purchase hesitation patterns. Geographic lifestyle shifts. Seasonal interest changes. None of that exists in a snapshot of current state.
Now, I should be honest here — databases have transaction logs, and you can do analytics on those. But transaction logs record row-level mutations: SET column = value. Domain events record business actions with semantic meaning. The difference is the difference between “field changed” and “customer moved to Denver and started shopping for ski gear.” One is plumbing. The other is insight.
Why Hazelcast?
So you’re sold on event sourcing (or at least willing to keep reading). Why Hazelcast as the platform?
Because event sourcing needs three things to work well, and Hazelcast handles all of them:
Fast writes for the event stream. Events go into an IMap — in-memory, sub-millisecond. You’re not waiting for a disk flush on the critical path.
Real-time processing. Hazelcast’s Event Journal streams events to Jet pipelines as they arrive. No polling, no batch windows. Events flow through processing stages — persist to event store, update materialized view, publish to subscribers — as a continuous pipeline.
Fast reads from materialized views. Once the pipeline updates a view, queries against it are sub-millisecond IMap lookups. No joins, no aggregation at query time.
Add ITopic for pub/sub event distribution across services and native horizontal scaling across cluster nodes, and you’ve got a complete event sourcing infrastructure without bolting together five different technologies.
Core Concepts
Domain Events
A domain event represents something meaningful that happened in your business. In our framework, events extend DomainEvent:
public abstract class DomainEvent<D extends DomainObject<K>, K>
implements UnaryOperator<GenericRecord>, Serializable {
// Event identification
protected String eventId; // Unique ID (UUID)
protected String eventType; // e.g., "CustomerCreated"
protected String eventVersion; // For schema evolution
// Event metadata
protected String source; // Service that created it
protected Instant timestamp; // When it happened
// Domain object reference
protected K key; // Key of affected entity
// Traceability
protected String correlationId; // Links related events
// The key method: how does this event change state?
public abstract GenericRecord apply(GenericRecord currentState);
}
The apply() method is the interesting part — it defines how this event transforms current state into new state. Each event type implements its own version of this, which means the logic for “what does this event do?” lives with the event itself, not in some giant switch statement somewhere.
If you’ve spent time with Domain-Driven Design, you’ll notice that our DomainObject<K> is what DDD calls an aggregate root. Every event is scoped to exactly one aggregate — CustomerCreatedEvent belongs to the Customer aggregate, OrderPlacedEvent belongs to the Order aggregate. Consistency is enforced within the aggregate boundary: all events for a given customer are ordered and processed sequentially (we’ll see how Hazelcast’s partition threading makes this work in Part 2). Across aggregates — between a customer and an order, say — we accept eventual consistency and coordinate through sagas. We don’t go deep into DDD vocabulary in this series, but if you know the terminology, you’ll see the boundaries everywhere.
A Concrete Example
Here’s CustomerCreatedEvent from our eCommerce implementation:
public class CustomerCreatedEvent extends DomainEvent<Customer, String> {
public static final String EVENT_TYPE = "CustomerCreated";
private String email;
private String name;
private String address;
private String phone;
public CustomerCreatedEvent(String customerId, String email,
String name, String address) {
super(customerId); // Sets the key
this.eventType = EVENT_TYPE;
this.email = email;
this.name = name;
this.address = address;
}
@Override
public GenericRecord apply(GenericRecord currentState) {
// For creation events, ignore current state and create new
return GenericRecordBuilder.compact("Customer")
.setString("customerId", key)
.setString("email", email)
.setString("name", name)
.setString("address", address)
.setString("status", "ACTIVE")
.setInt64("createdAt", Instant.now().toEpochMilli())
.build();
}
}
Notice that apply() for a creation event ignores currentState entirely — there is no current state, we’re creating it. Update events would read from currentState and modify specific fields.
The Event Store
The event store is append-only. Events go in and they don’t come out (well, they come out for reads, but they’re never modified or deleted). It’s the permanent, immutable record of everything that happened.
public interface EventStore<D extends DomainObject<K>, K,
E extends DomainEvent<D, K>> {
void append(K key, GenericRecord eventRecord);
List<GenericRecord> getEventsForKey(K key);
void replayByKey(K key, Consumer<GenericRecord> eventConsumer);
long getEventCount();
}
Materialized Views
If events are the source of truth, how do you actually query current state without replaying the entire event history every time someone calls GET /customers/123? You don’t. You maintain materialized views.
A materialized view is a pre-computed projection — it gets updated incrementally as each event flows through the pipeline. Think of it as a cache that’s always consistent with the event stream, because it’s derived from it.
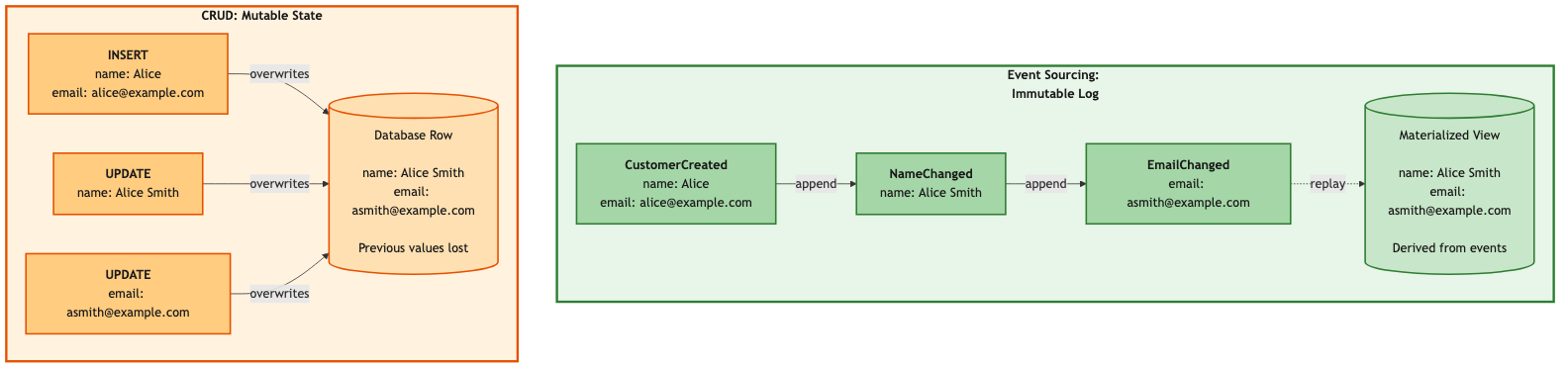
The view always reflects the latest state. Reads are instant — it’s just an IMap lookup.
The Event Flow
Here’s the full lifecycle of an event in our framework:
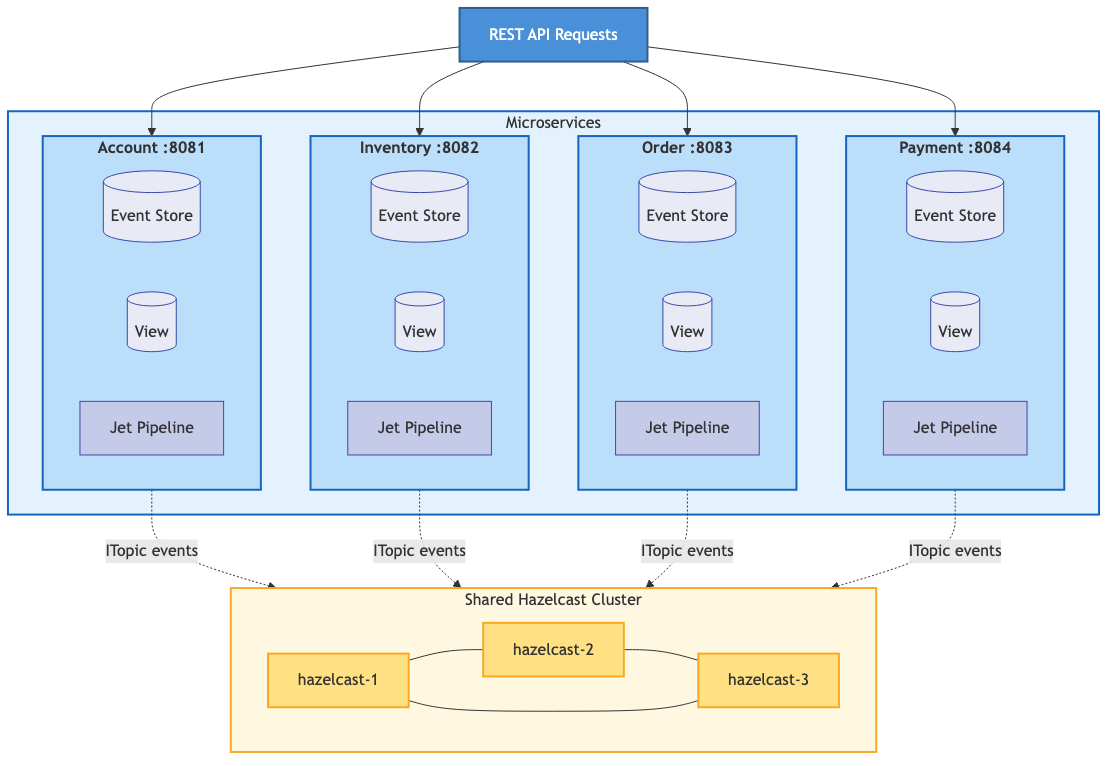
A REST request comes in. The service creates an event and drops it into the pending events IMap. The Jet pipeline picks it up via the Event Journal, then processes it through four stages: persist to the event store, update the materialized view, publish to subscribers via ITopic, and write a completion record. The API returns the customer data from the now-updated view.
That’s eight steps for what CRUD does in one database write. And yeah, that’s more moving parts. But each of those parts is doing something valuable — you get an audit trail, a materialized view, cross-service notification, and async completion tracking, all from a single event submission.
The Service Layer
Here’s what it looks like from the service code’s perspective:
@Service
public class AccountService {
private final EventSourcingController<Customer, String,
DomainEvent<Customer, String>> controller;
public CompletableFuture<Customer> createCustomer(CustomerDTO dto) {
CustomerCreatedEvent event = new CustomerCreatedEvent(
UUID.randomUUID().toString(),
dto.getEmail(),
dto.getName(),
dto.getAddress()
);
UUID correlationId = UUID.randomUUID();
return controller.handleEvent(event, correlationId)
.thenApply(completion -> {
return getCustomer(event.getKey()).orElseThrow();
});
}
public Optional<Customer> getCustomer(String customerId) {
GenericRecord gr = controller.getViewMap().get(customerId);
if (gr == null) return Optional.empty();
return Optional.of(Customer.fromGenericRecord(gr));
}
}
The service creates an event, not a database record. handleEvent() returns a CompletableFuture that completes when the pipeline has processed the event all the way through. And reads come from the materialized view — no event replay, just a fast IMap lookup.
Benefits in Practice
The architectural arguments are nice, but let’s see what this actually looks like when you’re debugging at 2am or fielding a compliance request.
Audit Trail
Every change is recorded. Every single one.
List<GenericRecord> history = eventStore.getEventsForKey("cust-123");
for (GenericRecord event : history) {
System.out.println(event.getString("eventType") + " at " +
event.getInt64("timestamp"));
}
CustomerCreated at 1706374800000 CustomerUpdated at 1706375100000 CustomerAddressChanged at 1706461200000
No special audit logging framework. No triggers on database tables. The event store is the audit trail, because it’s the source of truth.
Time Travel
Need to see what the data looked like last Thursday?
GenericRecord pastState = null;
for (GenericRecord event : eventStore.getEventsForKey("cust-123")) {
if (event.getInt64("timestamp") > targetTime) break;
pastState = applyEvent(event, pastState);
}
Replay events up to the timestamp you care about and stop. You now have the exact state of that entity at that moment. Try doing that with a database that only stores current state.
View Rebuilding
Found a bug in your view update logic? Fix the code and rebuild:
viewUpdater.rebuild(eventStore);
Clear the view, replay all events through the corrected logic, done. With CRUD, if your update logic had a bug that corrupted data, that data is just… corrupted. The correct values are gone. You’re restoring from backups and hoping for the best.
Service Independence
The Order service doesn’t call Account to get customer names. It has its own materialized view built from customer events:
EnrichedOrderView {
orderId: "order-456",
customerId: "cust-123",
customerName: "Alice Smith", // From CustomerCreated/Updated events
customerEmail: "alice@example.com",
items: [...],
total: 299.99
}
Each service maintains the views it needs for its own work. No cross-service calls at query time.
Performance
All the numbers here are from a single Apple MacBook Pro (M4 chip, 16GB RAM) running all services via Docker Compose. This is a baseline — the framework is designed to scale horizontally across Hazelcast cluster nodes and Kubernetes replicas, so treat these as a floor, not a ceiling.
The materialized view layer — the raw speed of IMap operations inside the JVM, bypassing HTTP entirely:
| Metric | Value |
|---|---|
| View update throughput | 100,000+ ops/second |
| P99 latency | < 1ms |
| View read latency | < 0.5ms |
End-to-end through the full pipeline (REST → event store → Jet → view update → ITopic publish):
| Metric | Value |
|---|---|
| Throughput | ~300+ TPS |
That end-to-end number is using curl in bash subshells as the load driver, which is about the least efficient way to generate HTTP load (every request forks a process and opens a new connection). A proper load testing tool with connection pooling — wrk, k6, Gatling — would push that number higher for the same pipeline.
What’s Next?
This was the foundation — what event sourcing is, why you’d use it, and how it works with Hazelcast. The series continues with deeper dives into the individual components:
- Building the event pipeline with Hazelcast Jet
- Materialized views for fast queries
- Observability in event-sourced systems
- The saga pattern for distributed transactions
- Vector similarity search with Hazelcast
- AI-powered microservices with MCP
- Circuit breakers and resilience patterns
- Transactional outbox and exactly-once delivery
- Dead letter queues and idempotency
- Performance engineering at scale
…and more as the framework evolves.
Getting Started
The complete framework is on GitHub — full source code, Docker Compose setup, a sample eCommerce application, load testing tools, and over 2,000 tests.
git clone https://github.com/myawnhc/hazelcast-microservices-framework cd hazelcast-microservices-framework ./scripts/docker/start.sh ./scripts/load-sample-data.sh ./scripts/demo-scenarios.sh
Event sourcing asks you to shift your thinking from “store what the world looks like” to “record what happened.” It’s a different mental model, and it takes some getting used to. But the payoff — real service decoupling, a complete audit trail, time travel debugging, views you can rebuild from scratch, and an event stream that’s ready for AI to mine — makes it worth the adjustment for a lot of systems.
That’s where we’ll leave things for today.
Next up: Building the Event Pipeline with Hazelcast Jet

Leave a comment